[딥러닝 파이토치 교과서] 4장. 딥러닝 시작
4.1 인공 신경망의 한계와 딥러닝 출현
인공 신경망에서 이용하는 구조
퍼셉트론 : 선형 분류기
다수의 신호를 입력으로 받아 하나의 신호를 출력한다.
이 신호를 입력으로 받아 흐른다/안 흐른다(1/0)는 정보를 앞으로 전달한다.

AND 게이트
- 모든 입력이 1일 때 작동한다
- 입력 중 하나라도 0을 갖는다면 작동을 멈춘다

데이터 분류로 표현

OR 게이트
- 둘 중 하나만 1이어도 작동한다
- 입력 모두가 0을 갖는 경우를 제외한 나머지가 작동한다

데이터 분류로 표현

XOR 게이트
- 둘 중 하나만 1일 때 작동한다

데이터 분류로 표현

데이터가 비선형적으로 분리되기 때문에 제대로 된 분류가 어렵다
단층 퍼셉트론에서는 XOR에 대한 학습이 불가능하다.
-> 이를 극복하는 방안으로 입력층과 출력층 사이에 은닉층을 두어 비선형적으로 분리되는 데이터에 대해서도 학습이 가능하도록 다층 퍼셉트론을 고안하였다.
입력층과 출력층 사이에 은닉층이 여러 개 있는 신경망을 심층 신경망, 즉 딥러닝이라고 한다.
4.2 딥러닝 구조
딥러닝 구조
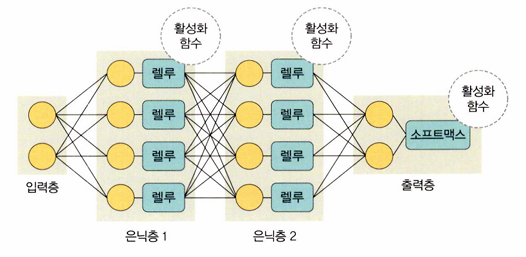
입력층, 출력층과 두 개 이상의 은닉층으로 구성되어 있다
딥러닝 구성 요소


- 가중치
: 입력 값이 연산 결과에 미치는 영향력을 조절하는 요소

- 가중합 또는 전달 함수
: 각 노드에서 들어오는 신호에 가중치를 곱해서 다음 노드로 전달되는데, 이 값들을 모두 더한 합계

(바이어스 역할 : 모델의 편향을 보정)
- 활성화 함수
: 전달받은 값을 출력할 때 일정 기준에 따라 출력 값을 변화시키는 비선형 함수
- 시그모이드 함수 : 0~1 사이의 비선형 형태로 변형. 로지스틱 회귀같은 분류 문제에서 사용된다. 기울기 소멸 문제가 발생하여 딥러닝 모델에서는 잘 사용하지 않는다


- 하이퍼볼릭 탄젠트 함수 : -1~1 사이의 비선형 형태로 변형. 시그모이드에서 결괏값의 평균이 0이 아닌 양수로 편향되는 문제를 해결했지만 기울기 소멸 문제는 여전히 발생한다


- 렐루 함수 : 입력이 음수일 때는 0을 출력하고 양수일 때는 x를 출력한다. 경사 하강법에 영향을 주지 않아 학습 속도가 빠르고 기울기 소멸 문제가 발생하지 않는다. 일반적으로 은닉층에서 사용된다


- 리키 렐루 함수 : 입력 값이 음수이면 0.001처럼 매우 작은 수를 반환한다. 입력 값이 수렴하는 구간이 제거된다


- 소프트맥스 함수 : 0~1 사이에 출력되도록 정규화하여 출력 값들의 총합이 항상 1이 되도록 한다. 보통 출력 노드의 활성화 함수로 많이 사용된다.

n : 출력층의 뉴런 개수
y_k : k번째 출력
a_k : 입력 신호
렐루 함수와 소프트맥스 함수를 구현하는 코드
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 은닉층
self.relu = torch.nn.ReLU(inplace = True)
self.out = torch.nn.Linear(n_hidden, n_output) # 출력층
self.softmax = torch.nn.Softmax(dim=n_output)
def forward(self, x):
x = self.hidden(x)
x = self.relu(x) # 은닉층을 위한 렐루 활성화 함수
x = self.out(x)
x = self.softmax(x) # 출력층을 위한 소프트맥스 활성화 함수
return x
- 손실 함수
: 경사 하강법은 학습률과 손실 함수의 순간 기울기를 이용하여 가중치를 업데이트하는 방법이다.
즉, 미분의 기울기를 이용하여 오차를 최소화하는 방향으로 이동시킨다.
이 때 오차를 구하는 방법이 손실 함수이다
- 평균 제곱 오차(MSE) : 실제 값과 예측 값의 차이를 제곱하여 평균을 낸 것. 회귀에서 손실함수로 주로 사용된다

구현 코드
import torch
loss_fn = torch.nn.MSELoss(reduction='sum') # sum : 모든 샘플의 손실을 합하여 총 손실을 구하겠다
loss = loss_fn(y_pred, y)
- 크로스 엔트로피 오차(CEE) : 분류 문제에서 원-핫 인코딩했을때만 사용할 수 있는 오차 계산법

학습이 지역 최소점에서 멈추는 것을 방지하고자 자연 상수 e에 반대되는 자연 로그를 모델의 출력 값에 취한다.
(작은 확률 값에 대해 큰 패널티를 부여하므로 정확하게 예측할 수 있도록 돕는다.)
구현 코드
loss = nn.CrossEntropyLoss()
input = torch.randn(5, 6, requires_grad=True) # 평균이 0이고 표준편차가 1인 가우시안 정규분포를 이용해 숫자 생성
target = torch.empty(3, dtype=torch.long).random_(5) # 3개의 원소를 가진 1차원 텐서 생성(임의의 정수가 0부터 4사이 값으로 설정)
output = loss(input, target)
output.backward()입력 텐서(input)와 타겟 텐서(target)의 크기가 맞지 않아도 동작한다.
이 경우에는 입력 텐서(input)의 첫 번째 차원이 타겟 텐서(target)의 크기에 맞게 변환된다. 따라서 입력 텐서(input)의 모양(shape)은 (N, C)이고, 타겟 텐서(target)는 크기 N을 가지게 된다. 여기서 N은 데이터의 개수를 의미하고, C는 클래스의 개수를 의미한다.
딥러닝 학습
순전파 (feedforward)
: 모든 뉴런이 이전 층의 뉴런에서 수신한 정보에 변환을 적용하여 다음 층의 뉴런으로 전송하는 방식
모든 뉴런이 계산을 완료하면 그 예측 값은 출력층에 도달한다.
그 다음 손실 함수로 네트워크의 예측 값과 실제 값의 차이를 추정한다.
손실 함수 비용이 0에 가깝도록 하기 위해 모델이 훈련을 반복하면서 가중치를 조정한다.
역전파 (backpropagation)
: 출력층에서 시작된 손실 비용은 은닉층의 모든 뉴런으로 전파되지만, 은닉층의 뉴런은 각 뉴런의 가중치에 따라 값이 달라진다.
즉, 예측 값과 실제 값의 차이를 각 뉴런의 가중치로 미분한 후 기존 가중치 값에서 뺀다.
이 과정을 출력층 -> 은닉층 -> 입력층 순서로 모든 뉴런에 대해 진행하여 계산된 각 뉴런 결과를 또다시 순전차의 가중치 값으로 사용한다.
딥러닝의 문제점과 해결 방안
딥러닝의 핵심 : 활성화 함수가 적용된 여러 은닉층을 결합하여 비선형 영역을 표현하는 것!!

활성화 함수가 적용된 은닉층 개수가 많을수록 데이터 분류가 잘되고 있다.
은닉층이 많은 경우 3가지 문제점
1. 과적합 문제 발생
: 훈련 데이터를 과하게 학습할 경우 실제 데이터에 대한 오차가 증가한다.
훈련 데이터를 과하게 학습하면 예측 값과 실제 값 차이인 오차는 감소하지만, 검증 데이터에 대해서는 오차가 증가할 수 있다.

과적합을 해결하는 방법 : 드롭아웃 (dropout) - 학습 과정 중 임의로 일부 노드들을 학습에서 제외시킨다.

드롭아웃 구현 코드
class DropoutModel(torch.nn.Module):
def __init__(self):
super(DropoutModel, self).__init__()
self.layer1 = torch.nn.Linear(784, 1200)
self.dropout1 = torch.nn.Dropout(0.5) # 50%의 노드를 무작위로 선택하여 사용하지 않겠다는 의미
self.layer2 = torch.nn.Linear(1200, 1200)
self.dropout2 = torch.nn.Dropout(0.5)
self.layer3 = torch.nn.Linear(1200, 10)
def forward(self, x):
x = F.relu(self.layer1(x))
x = self.dropout1(x)
x = F.relu(self.layer2(x))
x = self.dropout2(x)
return self.layer3(x)
2. 기울기 소멸 문제 발생
: 출력층에서 은닉층으로 전달되는 오차가 크게 줄어들어 학습이 되지 않는 현상
즉, 기울기가 소멸되기 때문에 학습되는 양이 '0'에 가까워져 학습이 더디게 진행되다 오차를 더 줄이지 못하고 그 상태로 수렴하는 현상
기울기 소멸 문제를 해결하는 방법 : ReLU 활성화 함수를 사용한다
3. 성능이 나빠지는 문제 발생
: 경사 하강법은 손실 함수의 비용이 최소가 되는 지점을 찾을 때까지 기울기가 낮은 쪽으로 계속 이동시키는 과정을 반복하는데, 이때 성능이 나빠지는 문제가 발생한다
성능이 나빠지는 문제를 해결하는 방법 : 확률적 경사 하강법, 배치 경사 하강법

1) 배치 경사 하강법
: 전체 데이터셋에 대한 오류를 구한 후 기울기를 한 번만 계산하여 모델의 파라미터를 업데이트한다
즉, 전체 훈련 데이터셋에 대해 가중치를 편미분한다

단점 : 한 스텝에 모든 훈련 데이터셋을 사용하므로 학습이 오래 걸린다
2) 확률적 경사 하강법
: 임의로 선택한 데이터에 대해 기울기를 계산하는 방법
적은 데이터를 사용하므로 빠른 계산이 가능하다

3) 미니 배치 경사 하강법
: 전체 데이터셋을 미니 배치 여러개로 나누고, 미니 배치 한 개마다 기울기를 구한 후 그것의 평균 기울기를 이용하여 모델을 업데이트해서 학습하는 방법

빠르고, 확률적 경사 하강법보다 안정적이기 때문에 가장 많이 사용한다

미니배치 경사 하강법 구현 코드
class CustomDataset(Dataset):
def __init__(self):
# 입력 데이터(x_data)와 출력 데이터(y_data)를 초기화합니다.
self.x_data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
self.y_data = [[12], [18], [11]]
def __len__(self):
# 데이터셋의 총 샘플 수를 반환합니다.
return len(self.x_data)
def __getitem__(self, idx):
# 인덱스(idx)에 해당하는 샘플의 입력 데이터와 출력 데이터를 반환합니다.
x = torch.FloatTensor(self.x_data[idx]) # 입력 데이터를 텐서로 변환합니다.
y = torch.FloatTensor(self.y_data[idx]) # 출력 데이터를 텐서로 변환합니다.
return x, y
dataset = CustomDataset()
dataloader = DataLoader(
dataset, # 데이터셋
batch_size = 2, # 미니 배치 크기로 2의 제곱수를 사용하겠다
shuffle = True # 데이터를 불러올 때마다 랜덤으로 섞어서 가져온다
)
* 옵티마이저 (optimizer)
: 학습 속도와 운동량을 조정해 확률적 경사 하강법의 파라미터 변경 폭이 불안정한 문제를 해결할 수 있다
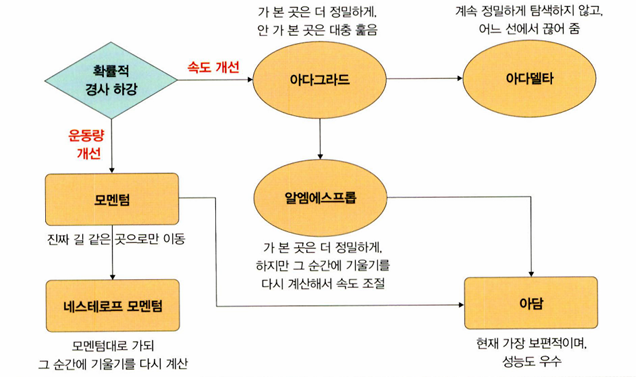
<속도를 조정하는 방법>
- RMSProp
: 변수의 업데이트 횟수에 따라 학습률을 조정하는 방법인 아다그라드에서 G(i) 값이 무한히 커지는 것을 방지하고자 제안된 방법
G 값이 너무 크면 학습률이 작아져 학습이 안될 수 있으므로 사용자가 γ 값을 이용하여 학습률 크기를 비율로 조정할 수 있도록 한다
optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01)
<운동량을 조정하는 방법>
- Momentum
: 경사 하강법과 마찬가지로 매번 기울기를 구하지만, 가중치를 수정하기 전에 이전 수정 방향(+, -)을 참고하여 같은 방향으로 일정한 비율만 수정하는 방법
수정이 + 방향과 - 방향으로 일어나는 지그재그 현상이 줄어들고, 이전 이동 값을 고려하여 일정 비율만큼 다음 값을 결정하므로 관성 효과를 얻을 수 있다
보통 확률적 경사 하강법(SGD)과 함께 사용한다

optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
- NAG (네스테로프 모멘텀)
: 모멘텀 값과 기울기 값이 더해져 실제 값을 만드는 기존 모멘텀과 달리 모멘텀 값이 적용된 지점에서 기울기 값을 계산한다
모멘텀으로 절반 정도 이동한 후 어떤 방식으로 이동해야 하는지 다시 계산하여 결정하기 때문에 모멘텀 방법의 단점을 극복할 수 있다. 따라서 빠른 이동 속도는 유지하면서 멈추어야 할 적절한 시점에서 제동을 건다.

모멘텀과 달리 이전에 학습했던 속도와 현재 기울기에서 이전 속도를 뺀 변화량을 더해서 가중치를 구한다.

optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=True)
<속도와 운동량에 대한 혼용 방법>
- Adam
: 모멘텀과 RMSProp의 장점을 결합한 경사 하강법
RMSProp의 특징인 기울기 제곱을 지수 평균한 값과 모멘텀 특징인 v(i)를 수식에 활용한다

optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
딥러닝을 사용할 때 이점
1. 특성 추출
: 데이터별로 어떤 특징을 가지고 있는지 찾아내고, 그것을 토대로 데이터를 벡터로 변환하는 작업
머신 러닝 알고리즘인 SVM, 나이브 베이즈, 로지스틱 회귀 등과 다르게 특성 추출 과정을 알고리즘에 통합시켰다. 데이터의 특성을 잘 잡아내고자 은닉층을 깊게 쌓는 방식으로 파라미터를 늘렸다
2. 빅데이터의 효율적 활용
: 데이터 사례가 많을수록 성능이 향상된다
4.3 딥러닝 알고리즘
심층 신경망
딥러닝 알고리즘은 심층 신경망을 사용한다는 공통점이 있다
심층신경망
: 입력층과 출력층 사이에 다수의 은닉층을 포함하는 인공 신경망

연산량이 많고 기울기 소멸 문제 등이 발생할 수 있기 때문에 드롭아웃, 렐루 함수, 배치 정규화 등을 적용해야 한다
합성곱 신경망 (CNN)
합성곱 신경망
: 합성곱층과 풀링층을 포함하는 이미지 처리 성능이 좋은 인공 신경망 알고리즘
- 영상 및 사진이 포함된 이미지 데이터에서 객체를 탐색하거나 객체 위치를 찾아내는 데 유용하다
- 이미지에서 객체, 얼굴, 장면을 인식하기 위해 패턴을 찾는 데 유용하다

합성곱 신경망의 특징
- 각 층의 입출력 형상을 유지한다
- 이미지의 공간 정보를 유지하면서 인접 이미지와 차이가 있는 특징을 효과적으로 인식한다
- 복수 필터로 이미지의 특징을 추출하고 학습한다
- 추출한 이미지의 특징을 모으고 강화하는 풀링층이 있다
- 필터를 공유 파라미터로 사용하기 때문에 학습 파라미터가 매우 적다
순환 신경망 (RNN)
순환 신경망
: 시계열 데이터(음악, 영상 등) 같은 시간 흐름에 따라 변화하는 데이터를 학습하기 위한 인공 신경망

순환 신경망의 특징
- 시간성을 가진 데이터가 많다
- 시간성 정보를 이용하여 데이터의 특징을 잘 다룬다
- 시간에 따라 내용이 변하므로 데이터는 동적이고, 길이가 가변적이다
- 매우 긴 데이터를 처리하는 연구과 활발히 진행되고 있다
순환 신경망을 기울기 소멸 문제로 학습이 제대로 되지 않는 문제가 있다. 이를 해결하고자 메모리 개념을 도입한 LSTM이 많이 사용되고 있다
제한된 볼츠만 머신
볼츠만 머신
: 가시층과 은닉층으로 구성된 모델. 가시층은 은닉층과만 연결된다
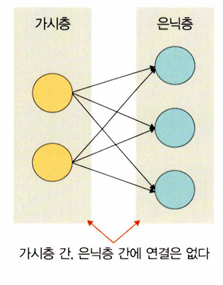
제한된 볼츠만 머신의 특징
- 차원 감소, 분류, 선형 회귀 분석, 협업 필터링, 특성 값 학습, 주제 모델링에 사용한다
- 기울기 소멸 문제를 해결하기 위해 사전 학습 용도로 활용 가능하다
- 심층 신뢰 신경망의 요소로 활용된다
심층 신뢰 신경망
심층 신뢰 신경망 (Deep Belief Network, DBN)
: 입력층과 은닉층으로 구성된 제한된 볼츠만 머신을 블록처럼 여러 층으로 쌓은 형태로 연결된 신경망
즉, 사전 훈련된 제한된 볼츠만 머신을 층층이 쌓아 올린 구조
레이블이 없는 데이터에 대한 비지도 학습이 가능하다
부분적인 이미지에서 전체를 연상하는 일반화와 추상화 과정을 구현할 때 유용하다

심층 신뢰 신경망의 특징
- 순차적으로 DBN을 학습시켜 가면서 계층적 구조를 생성한다
- 비지도 학습으로 학습한다
- 위로 올라갈수록 추상적 특성을 추출한다
- 학습된 가중치를 다층 퍼셉트론의 가중치 초깃값으로 사용한다
4.4 우리는 무엇을 배워야 할까
머신러닝 - 간단한 선형 회귀 분류
딥러닝 - 복잡한 비선형 데이터에 대한 분류 및 예측
데이터를 활용하여 얻고자 하는 것에 따라 머신러닝이나 딥러닝을 선택해서 학습하고 데이터를 훈련시키면 된다