[딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(1)
6.1 이미지 분류를 위한 신경망
입력 데이터로 이미지를 사용한 분류는 특정 대상이 영상 내에 존재하는지 여부를 판단하는 것이다.
이미지 분류에서 주로 사용되는 합성곱 신경망 유형은 다음과 같다
6.1.1 LeNet-5
- 합성곱 신경망이라는 개념을 최초로 개발하였다
- 합성곱(convolutional)과 다운 샘플링(sub-sampling)을 반복적으로 거치면서 마지막에 완전연결층에서 분류를 수행한다
합성곱 - 이미지에서 특징 추출해 특징 맵 생성
다운 샘플링 - 특징 맵의 크기를 줄임

C : 합성곱층, S : 풀링층, F : 완전연결층
- C1에서 5x5 합성곱 연산 후 28x28 크기의 feature map 6개를 생성한다
- S2에서 다운 샘플링하여 feature map 크기를 14x14로 줄인다
- C3에서 5x5 합성곱 연산하여 10x10 크기의 feature map 16개를 생성한다
- S4에서 다운 샘플링하여 feature map 크기를 5x5로 줄인다
- C5에서 5x5 합성곱 연산하여 1x1 크기의 feature map 120개를 생성한다
- F6에서 완전연결층으로 C5의 결과를 유닛 84개에 연결시킨다
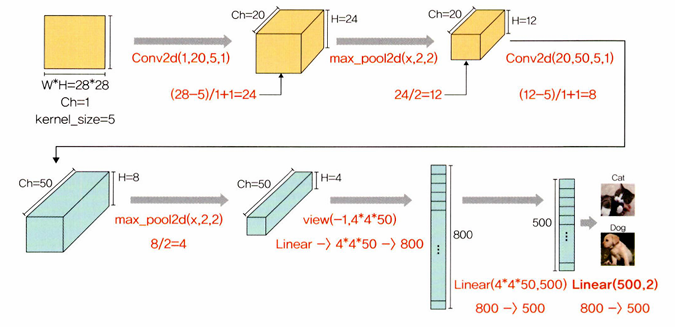
LeNet-5 예제 구현

32x32 크기의 이미지에 합성곱층과 최대 풀링층이 쌍으로 두 번 적용된 후 완전연결층을 거쳐 이미지가 분류되는 신경망이다.

<이미지 데이터셋을 불러온 후 훈련, 검증, 테스트로 분리>
cat_images_filepaths = sorted([os.path.join(cat_directory, f) for f in os.listdir(cat_directory)])
sorted : 데이터를 정렬된 리스트로 만들어서 반환한다
os.path.join : cat_directory와 os.listdir을 통해 검색된 이미지 파일들(f)을 하나로 합쳐서 표시해준다
os.listdir : 지정한 디렉터리 내 모든 파일의 리스트를 반환한다
<합성곱층과 풀링층의 크기 계산>
6.1.2 AlexNet
- ImageNet 영상 데이터베이스 기반
CNN 구조 다시 살펴보기

- 너비, 높이, 깊이의 3차원 구조를 갖는다
- 색상이 많은 이미지는 R/G/B 성분 3개를 갖기 때문에 시작이 3이지만, 합성곱을 거치면서 특성 맵이 만들어지고 이것에 따라 중간 영상의 깊이가 달라진다
AlexNet 구조

- 합성곱층 총 5개와 완전연결층 3개
- 마지막 완전연결층은 카테고리 1000개를 분류하기 위해 softmax 활성화 함수를 사용하고 있다
- GPU 2개를 기반으로 한 병렬 구조인 점을 제외하면 LeNet-5와 크게 다르지 않다
- 합성곱층에서 사용된 활성화 함수는 ReLU

- 학습 가능한 변수가 총 6600만 개 있다
- 입력은 227x227x3크기의 RGB이미지이며, 각 클래스에 해당하는 1000x1 확률 벡터를 출력한다
- 첫번째 합성곱층 커널의 크기는 11x11x3이며, stride를 4로 적용해 55x55x96의 출력을 갖는다
- 첫번째 계층을 거치면서 GPU-1에서는 주로 컬러와 상관없는 정보를 추출하기 위한 커널이 학습된다
- GPU-2에서는 주로 컬러와 관련된 정보를 추출하기 위한 커널이 학습된다
AlexNet GPU-1,2 적용 결과

6.1.3 VGGNet
- 합성곱층의 파라미터 수를 줄이고 훈련 시간을 개선하려고 탄생했다
- 네트워크를 깊게 만드는 것이 성능에 어떤 영향을 미치는지 확인하고자 나온 것이다
- 깊이의 영향만 최대한 확인하고자 합성곱층에서 사용하는 필터/커널의 크기를 가장 작은 3x3으로 고정했다
- 네트워크 계층의 총 개수에 따라 VGG16, VGG19 등 여러 유형이 있다
VGG16
- 파라미터가 총 1억 3300만 개 있다
- 모든 합성곱 커널의 크기는 3x3, 최대 풀링 커널의 크기는 2x2, 스트라이드는 2
- 64개의 224x224 특성 맵들이 생성된다
- 마지막 16번째 계층을 제외하고는 모두 ReLU 활성화 함수가 적용된다
VGG16 구조

- VGG11 - 합성곱층 8개, 완전연결층 3개 = 전체 계층 11개
- VGG13 - 합성곱층 10개, 완전연결층 3개 = 전체 계층 13개
- VGG16 - 합성곱층 13개, 완전연결층 3개 = 전체 계층 16개
- VGG19 - 합성곱층 16개, 완전연결층 3개 = 전체 계층 19개
# of params 계산
(output ch) * (input ch) * (kernel size) + (# of filters)
weight bias
VGG11 예제 구현
<필요한 라이브러리 호출>
객체 복사
- 얕은 복사 (shallow copy)
- 깊은 복사 (deep copy)
단순한 객체 복사
original = [1, 2, 3]
copy_o = original # copy_o에 original 복사 (shallow copy)
print(copy_o)
copy_o[2] = 10
print(copy_o)
print(original)실행결과
[1, 2, 3]
[1, 2, 10]
[1, 2, 10]
- copy_o뿐만 아니라 원래 값인 original의 3도 10으로 바뀌었다
얕은 복사 - copy.copy() 이용
import copy
original = [[1, 2], 3]
copy_o = copy.copy(original) # original 값을 copy_o에 얕은 복사(copy.copy())
print(copy_o)
copy_o[0] = 100 # copy_o의 [1, 2] 값을 100으로 변경
print(copy_o)
print(original)
append = copy.copy(original)
append[0].append(4) # 첫번째 리스트([1, 2])에 4를 추가
print(append)
print(original)실행결과
[[1, 2], 3]
[100, 3]
[[1, 2], 3]
[[1, 2, 4], 3]
[[1, 2, 4], 3]
- copy_o만 [1, 2]의 값이 100으로 바뀌었다
- [1, 2]에 4를 추가했더니 original과 copy_o 모두 반영되었다
깊은 복사 - copy.deepcopy() 이용
import copy
original = [[1, 2], 3]
copy_o = copy.deepcopy(original) # original 값을 copy_o에 깊은 복사(copy.deepcopy())
print(copy_o)
copy_o[0] = 100 # copy_o의 [1, 2] 값을 100으로 변경
print(copy_o)
print(original)
append = copy.deepcopy(original)
append[0].append(4) # 첫번째 리스트([1, 2])에 4를 추가
print(append)
print(original)실행결과
[[1, 2], 3]
[100, 3]
[[1, 2], 3]
[[1, 2, 4], 3]
[[1, 2], 3]
- copy_o에서 [1, 2] 값을 100으로 변경했더니 copy_o만 바뀌었다
- [1, 2]에 4를 추가했더니 copy_o는 변경되었지만 original은 그대로이다
단순 복사 vs 얕은 복사 vs 깊은 복사
| copy_o에서 [1, 2]값 변경 | [1, 2]에 4를 추가 | |
| 단순 복사 | copy_o와 original 둘다 바뀜 | |
| 얕은 복사(shallow copy) | copy_o만 바뀜 | copy_o와 original 둘다 추가됨 |
| 깊은 복사(deep copy) | copy_o만 바뀜 | copy_o만 추가됨 |
얕은 복사 vs 깊은 복사

<모델 유형 정의>
VGG11, VGG13, VGG16, VGG19 네트워크

<사전 학습된 VGG 모델>
- VGG 모델은 사실 사전 훈련된 모델이다
- 이미 누군가가 대용량의 이미지 데이터로 학습을 시켰다
- 최상의 상태로 튜닝을 거쳐 모든 사람이 사용할 수 있도록 공유했다
<ImageFolder>
훈련 데이터셋이 '../chap06/data/catanddog/train'에 위치해있을 때
train 폴더 하위에 Cat, Dog 폴더가 계층적으로 위치해 있고
이러한 구조에서 데이터셋을 불러오고 싶을 때 ImageFolder를 사용한다
<torch.cat>
dim=0 : 행을 기준으로 이어 붙임
dim=1 : 열을 기준으로 이어 붙임
<torch.add vs torch.add_>
x = torch.tensor([1, 2])
y = x.add(10) # torch.add 적용
print(y)
print(x is y)
print('----------')
y = x.add_(10) # torch.add_ 적용
print(y)
print(x is y)
tensor([11, 12])
False -> 새로운 메모리 공간이 할당되어 저장되었다
----------
tensor([11, 12])
True -> 기존의 메모리에 위치한 값을 대체한다
6.1.4 GoogLeNet
- 주어진 하드웨어 자원을 최대한 효율적으로 이용하면서 학습 능력은 극대화할 수 있는 깊고 넓은 신경망이다
- 깊고 넓은 신경망을 위해 Inception 모듈을 추가했다
- 인셉션 모듈에서는 특징을 효율적으로 추출하기 위해 1x1, 3x3, 5x5의 합성곱 연산을 각각 수행한다
- 3x3 최대 풀링은 입력과 출력의 높이와 너비가 같아야 하므로 패딩을 추가해야 한다
- 결과적으로 GoogLeNet에 적용된 해결 방법은 희소 연결(sparse connectivity)이다
- 희소 연결 : 빽빽하게 연결된 신경망 대신 관련성이 높은 노드끼리만 연결하는 방법
- 희소 연결로 연산량이 적어지며 과적합도 해결할 수 있다
GoogLeNet의 인셉션 모듈

- 1x1 합성곱
- 1x1 합성곱 + 3x3 합성곱
- 1x1 합성곱 + 5x5 합성곱
- 3x3 최대 풀링 + 1x1 합성곱
인셉션 모듈에서는 각각의 병렬 브랜치에서 계산된 출력을 합친 후에 다음 레이어로 전달한다. 이러한 병렬 구조를 통해 네트워크는 다양한 크기의 특징을 학습하고 입력 데이터의 복잡한 패턴을 더 잘 이해할 수 있게 된다.
6.1.5 ResNet
- 마이크로소프트에서 개발한 알고리즘이다
- 깊어진 신경망을 효과적으로 학습하기 위한 방법으로 residual 개념을 고안한 것이다
- 신경망 깊이가 깊어질수록 딥러닝 성능이 좋아질 것 같지만, "Deep Residual Learning for Image Recognition" 논문에 따르면 신경망은 깊이가 깊어질수록 성능이 좋아지다가 일정한 단계에 다다르면 오히려 성능이 나빠진다

- 그림을 보면 네트워크 56층이 20층보다 성능이 나쁜 것을 알 수 있다
- 네트워크의 깊이가 깊다고 해서 무조건 성능이 좋아지지는 않는다
- 이러한 문제를 해결하기 위해 residual block을 도입했다
- residual block은 기울기가 잘 전파될 수 있도록 shortcut을 만들어 준다
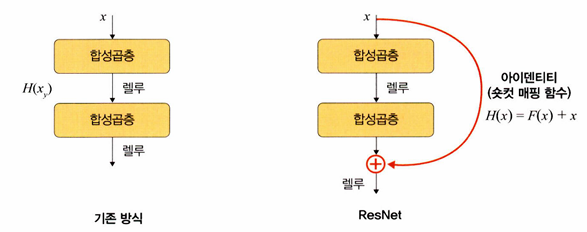
- ResNet은 층이 총 152개로 구성되어 기울기 소멸 문제가 발생할 수 있다
- 숏컷을 두어 기울기 소멸 문제를 방지했다
블록
- 블록은 계층의 묶음이다
- 합성곱층을 하나의 블록으로 묶은 것이다

- 색상별로 블록을 구분했다
- 이렇게 묶인 계층들을 하나의 residual block이라고 한다
- residual block을 여러 개 쌓은 것을 ResNet이라고 한다
- 하지만 계층을 계속해서 쌓아 늘리면 파라미터 수가 문제가 된다. 예를 들어 ResNet34는 합성곱층이 34개와 16개의 블록으로 구성되어 있다. 계층의 깊이가 깊어질수록 파라미터는 무제한으로 커진다. 이러한 문제를 해결하기 위해 병목 블록(bottleneck block)이라는 것을 두었다
병목 블록 (bottleneck block)

- 위의 그림은 ResNet34와 ResNet50이다
- ResNet34는 기본 블록을 사용하며, ResNet50은 병목 블록을 사용한다
- 기본 블록의 경우 파라미터 수가 39.3216M인 반면, 병목 블록의 경우 파라미터 수가 6.9632M이다. 깊이가 깊어졌음에도 파라미터 수는 감소하였다
- ResNet50에서는 3x3 합성곱층 앞뒤로 1x1 합성곱층이 붙어 있는데, 1x1 합성곱층의 채널 수를 조절하면서 차원을 줄였다 늘리는 것이 가능하기 때문에 파라미터 수를 줄일 수 있었다. 이 부분이 병목과 같다고 하여 병목 블록이라고 한다.
아이덴티티 매핑 (= 숏컷(shortcut), 스킵 연결(skip connection))
- 위의 그림에서 + 기호 부분을 말한다
- 입력 x가 어떤 함수를 통과하더라도 다시 x라는 형태로 출력되도록 한다
유튜브 강의 참고 - https://www.youtube.com/watch?v=Fypk0ec32BU
1. skip-connection?

- x가 들어와서 F(x)가 나가는 게 기존의 방법이라면, x + F(x)가 나가게끔 연결해준다 (여기서, F(x) = σ(xW1)W2)
- layer에 들어온 x를 받아서 만들고 싶은 이상적인 녀석이 H(x)라고 할 때, 이 녀석을 F(x)로 만들기 vs x + F(x)를 비교해보면 후자가 좋다. 왜?
- x로 H(x) ≈ x 를 만들고 싶다고 가정해보면 skip-connection이 없는 MLP라면 weight matrix는 x는 identity가 되어야 한다
- skip-connection이 있는 MLP라면 weight matrix는 0행렬이 되어야 한다
- weight는 0 근처로 초기화 되므로 누가 더 H(x) ≈ x 를 만들기 쉬울까? identity보다는 0행렬을 만드는 것이 쉽다
2. H(x) ≈ x ? 왜 만들고 싶은게 x랑 비슷할까?
- 엄청 깊다면 입력으로부터 차근차근 조금씩 값을 바꿔 나가는게 이상적이다
- 예를 들어, 잘 학습된 ResNet-50dms 34 -> 36층 갈 때 값의 변화가 그리 크진 않을 것이다. H(x) ≈ x일 것이다.
- 즉, skip-connection이 있을 때는 x랑 비슷한 H(x)를 만들기가 굉장히 쉽기 때문에 skip-connection을 연결해 준다는 것은 "값의 변화가 그리 크지 않을테니 layer 하나에서 모든걸 다 하려고 하지 말고 조금씩만 바꿔 나가라!"라고 AI에게 귀띔 해주는 셈이다
- 5:27

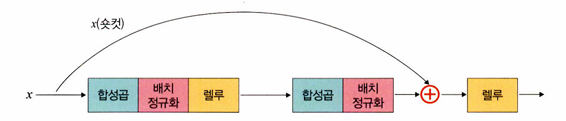
def forward(self, x):
i = x # 입력 x를 i라는 변수에 저장
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
if self.downsample is not None:
i = self.downsample(i) # 다운샘플 적용
x += I # 아이덴티티 매핑 적용
x = self.relu(x)
return x
예를 들어 x가 (28, 28, 64)라고 가정해보면 x를 i 변수에 저장했기 때문에 (28, 28, 64)가 된다. 그리고 합성곱층을 통과하면서 bn3까지 통과한 형태도 (28, 28, 64)이다. 같은 형태를 더하기 때문에 Element-wise sum이 되어 최종 형태도 (28, 28, 64)가 된다.
잔차 = 현재 학습하는 층의 입력과 출력 사이의 차이
차이가 0에 가까울수록, 해당 층은 입력을 거의 변경하지 않고 그대로 전달하는 것이다
아이덴티티 매핑은 잔차를 줄이는 데 도움을 준다
다운샘플(downsample)
- 특성맵 크기를 줄이기 위한 것
- 풀링과 같은 역할

보라색 영역의 첫 번째 블록에서 특성 맵의 형상이 (28, 28, 64)였다면 세 번째 블록의 마지막 합성곱층을 통과하고 아이덴티티 매핑까지 완료된 특성 맵의 형상도 (28, 28, 64)이다.
노란색 영역의 시작 지점에서는 채널 수가 128로 늘어났고, /2라는 것으로 보아 첫 번째 블록에서 합성곱층의 스트라이드가 2로 늘어나 (14, 14, 128)로 바뀐다는 것을 알 수 있다
즉, 보라색과 노란색의 형태가 다른데 형태를 맞추지 않으면 아이덴티티 매핑을 할 수 없다. 따라서 아이덴티티에 대해 다운샘플이 필요하다
입력과 출력의 형태를 같도록 맞추어 주기 위해서는 stride 2를 가진 1x1 합성곱 계층을 하나 연결해 주면 된다.
아이덴티티 블록 : 입력과 출력의 차원이 같은 것
프로젝션 숏컷(projection-shortcut) / 합성곱 블록 : 입력 및 출력 차원이 동일하지 않고 입력의 차원을 출력에 맞추어 변경해야 하는 것
합성곱 블록

아이덴티티 블록
정리하면 ResNet은 기본적으로 VGG19 구조를 뼈대로 하며, 거기에 합성곱층들을 추가해서 깊게 만든 후 숏컷들을 추가하는 것이다.
VGG19와 ResNet 비교
