[딥러닝 파이토치 교과서] 9장. 자연어 전처리
9.1 자연어 처리란
자연어 처리
: 우리가 일상생활에서 사용하는 언어 의미를 분석하여 컴퓨터가 처리할 수 있도록하는 과정
자연어 처리 완성도

9.1.1 자연어 처리 용어 및 과정
자연어 처리 관련 용어
1. 말뭉치(corpus(코퍼스))
: 자연어 처리에서 모델을 학습시키기 위한 데이터

2. 토큰(token)
: 자연어 처리를 위한 문서는 작은 단위로 나누어야 하는데, 이때 문서를 나누는 단위가 토큰이다.
- 토큰 생성(tokenizing) : 문자열을 토큰으로 나누는 작업
- 토큰 생성 함수 : 문자열을 토큰으로 분리하는 함수
3. 토큰화(tokenization)
: 텍스트를 문장이나 단어로 분리하는 것
- 토큰화 단계를 마치면 텍스트가 단어 단위로 분리된다.
4. 불용어(stop words)
: 문장 내에서 많이 등장하는 단어
- 빈도 때문에 성능에 영향을 미치므로 사전에 제거해 주어야 한다.
- "a", "the", "she", "he" 등이 있다.
5. 어간 추출(stemming)
: 단어를 기본 형태로 만드는 작업
- 예를 들어 'consign', 'consigned', 'consigning', 'consignment'가 있을 때 기본 단어인 'consign'으로 통일하는 것

6. 품사 태깅(part-of-speech tagging)
: 주어진 문장에서 품사를 식별하기 위해 붙여 주는 태그를 의미
- Det : 한정사
- Noun : 명사
- Verb : 동사
- Prep : 전치사
- 품사 태깅은 NLTK를 이용할 수 있다.
NLTK를 이용한 품사 태깅
- VBZ : 동사, 동명사 또는 현재 분사
- PRP : 인칭 대명사
- JJ : 형용사
- VBG : 동사, 동명사 또는 현재 분사
- NNS : 명사, 복수형
- CC : 등위 접속사
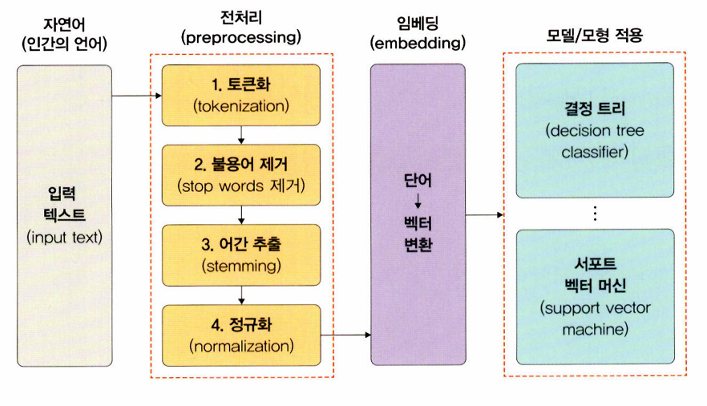
자연어 처리 과정
인간 언어는 컴퓨터가 이해할 수 없기 때문에 컴퓨터가 이해할 수 있는 언어로 바꾸고 원하는 결과를 얻기까지 크게 4단계를 거친다.
- 자연어가 입력 텍스트로 들어온다. (언어마다 처리 방식이 다르다)
- 입력된 텍스트에 대한 전처리 과정이 필요하다.
- 전처리가 끝난 단어들을 임베딩한다. (단어를 벡터로 변환하는 것)
- 모델을 이용해 데이터에 대한 분류 및 예측을 수행한다.
9.1.2 자연어 처리를 위한 라이브러리
NLTK(Natural Language Toolkit)
: 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 라이브러리
- 말뭉치
- 토큰 생성
- 형태소 분석
- 품사 태깅
등의 주요 기능을 제공한다.
KoNLPy(코엔엘파이)
: 한국어 처리를 위한 파이썬 라이브러리
- 형태소 분석
- 품사 태깅
등의 주요 기능을 제공한다.
형태소
: 언어를 쪼갤 때 의미를 가지는 최소 단위

Gensim
: 파이썬에서 제공하는 Word2Vec 라이브러리 (딥러닝 라이브러리는 아니지만 효율적이고 확장 가능하다)
- 임베딩 : Word2Vec
- 토픽 모델링 (각 주제별로 단어 표현을 묶어 주는 것)
- LDA(Latent Dirichlet Allocation) (각 문서에 어떤 주제들이 존재하는지를 서술하는 확률적 토픽 모델 기법)
등의 주요 기능을 제공한다.
사이킷런(scikit-learn)
: 파이썬을 이용하여 문서를 전처리할 수 있는 라이브러리 (자연어 처리에서 특성 추출 용도로 많이 사용된다)
- CountVectorizer : 텍스트에서 단어의 등장 횟수를 기준으로 특성을 추출한다.
- Tfidfvectorizer : TF-IDF 값을 사용해서 텍스트에서 특성을 추출한다.
- HashingVectorizer : CountVectorizer와 방법이 동일하지만 텍스트를 처리할 때 해시 함수를 사용하기 때문에 실행 시간이 감소한다.
9.2 전처리
머신 러닝이나 딥러닝에서 텍스트 자체를 특성으로 사용할 수는 없고 전처리 작업이 필요하다.
전처리 과정은 다음과 같다.

9.2.1 결측치 확인
결측치
: 주어진 데이터셋에서 데이터가 없는 것(NaN)
결측치를 처리하는 방법
- 데이터에 하나라도 NaN 값이 있을 때 행 전체를 삭제
- 데이터가 거의 없는 특성(열)은 특성(열) 자체를 삭제
- 최빈값 혹은 평균값으로 NaN 값을 대체
9.2.2 토큰화
토큰화(tokenization)
: 주어진 텍스트를 단어/문자 단위로 자르는 것
문장 토큰화와 단어 토큰화로 구분된다.
문장 토큰화
: 마침표, 느낌표, 물음표 등 문장의 마지막을 뜻하는 기호에 따라 분리하는 것
단어 토큰화
: 띄어쓰기를 기준으로 문장을 구분한다

9.2.3 불용어 제거
불용어(stop word)
: 문장 내에서 빈번하게 발생하여 의미를 부여하기 어려운 단어들
- 예를 들어 'a', 'the' 같은 단어들은 모든 구문에 매우 많이 등장하기 때문에 아무런 의미가 없다.
- 특히 불용어는 자연어 처리에 있어 효율성을 감소시키고 처리 시간이 길어지는 단점이 있기 때문에 반드시 제거가 필요하다.
9.2.4 어간 추출
어간 추출(stemming), 표제어 추출(lemmatization)
: 단어 원형을 찾아 주는 것
- 어간 추출은 단어 그 자체만 고려하기 때문에 품사가 달라도 사용 가능하다
- writing, writes, wrote -> write
- automates, automatic, automation -> automat
- 표제어 추출은 단어가 문장 속에서 어떤 품사로 쓰였는지 고려하기 때문에 품사가 같아야 사용 가능하다
- am, are, is -> be
- car, cars, car's, cars' -> car
- 어간 추출은 사전에 없는 단어도 추출할 수 있고 표제어 추출은 사전에 있는 단어만 추출할 수 있다
NLTK의 어간 추출
- porter와 lancaster 알고리즘
- 랭커스터 알고리즘은 단어 원형을 알아볼 수 없을 정도로 축소시키기 때문에 정확도가 낮다. 따라서 데이터셋을 축소시켜야 하는 특정 상황에서나 유용하다.
표제어 추출
- 일반적으로 어간 추출보다 표제어 추출의 성능이 더 좋다.
- 품사와 같은 문법뿐만 아니라 문장내에서 단어 의미도 고려하기 때문에 성능이 좋다.
- 어간 추출보다 시간이 더 오래 걸리는 단점이 있다.
- WordNetLemmatizer를 주로 사용한다.
- 두 번째 파라미터에 품사 정보를 넣어 주면 정확하게 어근 단어를 추출할 수 있다.
9.2.5 정규화
정규화(normalization)
: 데이터셋이 가진 특성의 모든 데이터가 동일한 정도의 범위를 갖도록 하는 것

- MonthlyIncome은 0~10000 의 범위를 갖는다
- RelationshipSatisfaction은 0~5 의 범위를 갖는다.
- 이 상태에서 데이터를 분석하면 MonthlyIncome 값이 더 크기 때문에 상대적으로 더 많은 영향을 미치게 된다.
- 값이 크다고 해서 더 중요한 요소인 것은 아니므로 정규화가 필요하다.
1. MinMaxScaler()
: 모든 칼럼이 0과 1 사이에 위치하도록 값의 범위로 조정한다
이상치의 경우 좁은 범위로 압축될 수 있기 때문에 주의해야 한다.

from sklearn.preprocessing import MinMaxScaler
minMaxScaler = MinMaxScaler() # MinMaxScaler 객체 생성
minMaxScaler.fit(train_Data) # 최소값과 최대값이 계산되어 저장됨
train_data_minMaxScaled = minMaxScaler.transform(train_data) # 입력 데이터를 정규화
2. StandardScaler()
: 각 특성의 평균을 0, 분산을 1로 변경하여 칼럼 값의 범위를 조정한다.

from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
standardScaler.fit(train_data)
train_data_standardScaled = standardScaler.transform(train_data)
3. RobustScaler()
: 평균과 분산 대신 중간값과 사분위수 범위를 사용한다.
StandardScaler() 와 비교하면 동일한 값이 더 넓게 분포되어 있다.

사분위수 범위(IQR)
사분위수 : 전체 관측 값을 오름차순으로 정렬한 후 전체를 사등분하는 값
- 제1사분위수 = Q1 = 제25백분위수
- 제2사분위수 = Q2 = 제50백분위수
- 제3사분위수 = Q3 = 제75백분위수
이때 제3사분위수와 제1사분위수 사이 거리를 사분위수 범위(IQR)라고 한다.
사분위수 범위 : IQR = 제3사분위수 - 제1사분위수 = Q3 - Q1
4. MaxAbsScaler()
: 절댓값이 0~1 사이가 되도록 조정한다.
즉, 모든 데이터가 -1~1 사이가 되도록 조정하기 때문에 양의 수로만 구성된 데이터는 MinMaxScaler()와 유사하게 동작한다.
데이터로더 이용
- 방대한 양의 데이터를 배치 단위로 쪼개서 처리할 수 있다.
- 데이터를 무작위로 섞을 수 있기 떄문에 효율적으로 데이터를 처리할 수 있다.
- 여러 개의 GPU를 사용하여 데이터를 병렬로 학습시킬 수 있다.
이진 분류에서 사용하는 손실 함수
- BCELoss(Binary Cross Entropy Loss)(이진 교차 엔트로피)
- BCEWithLogitLoss (BCELoss + sigmoid)