하나의 컴퓨터 비전 작업에서 잘 작동하는 신경망의 구조는 다른 작업에서도 잘 작동하는 경우가 많습니다.
<대표적인 신경망>
LeNet-5
AlexNet
VGG
ResNet
Inception
2. 고전적인 네트워크들
LeNet-5 구조가 있습니다 32 x 32 x 1 의 이미지가 있을 때 LeNet-5 의 목적은 손글씨의 숫자를 인식하는 것입니다
첫 번째로는 6 개의 5 x 5 필터와 1 의 스트라이드를 사용 -> 28 x 28 x 6 평균 풀링을 사용하고 필터 크기가 2 이고 스트라이드가 2 -> 14 x 14 x 6 두번째 합성곱 층을 적용하는데 16 개의 5 x 5 필터를 사용 -> 10 x 10 x 16 두번째 풀링 층 -> 5 x 5 x 16 = 400 완전 연결 층 -> 400 개의 노드를 120 개의 뉴런에 각각 연결해줍니다. 두번째 완전 연결 층 -> 120 개의 노드를 84 개의 뉴런에 각각 연결해줍니다. 마지막 과정은 이 84 개의 속성을 가지고 하나의 최종 출력에 적용합니다. 여기 노드 하나를 더 그려서 y 의 예측값을 나타내고 10 가지 가능성이 있는데 0 부터 9 까지의 숫자 인식에 해당합니다.
이 신경망은 요즘 기준으로 적은 60,000 개의 변수를 가집니다
<요즘도 활용되는 것> 1. 신경망의 왼쪽에서 오른쪽으로 이동할 때 높이와 너비가 32 에서 28 에서 14 에서 10 그리고 5 로 변하고 채널의 수는 1 에서 6 에서 16 으로 증가합니다 2. 몇 개의 합성곱 층 뒤에 풀링 층이 따라오고 또 합성곱 층에 풀링 층이 또 따라서 온 뒤 완전 연결 층이 있고 그 다음에 출력이 있는 것입니다
<지금은 사용되지 않는 것>
1. 당시에는 ReLU 비선형성을 사용하지 않았습니다. 대신 시그모이드와 tanh 비선형성을 사용했습니다.
2. 당시에는 컴퓨터가 훨씬 느려서 변수처럼 계산을 줄이기 위해 초기의 LeNet-5 는 각각의 필터가 서로 다른 채널에 적용되었습니다. 요즘에는 이런 복잡한 걸 사용하지 않습니다 .
3. 기존의 LeNet-5 는 비선형성이 풀링 뒤에 있었습니다.
만약 이 논문을 읽는다면 섹션 2 에 초점을 두는 것을 추천해 드립니다!
AlexNet 논문에서는 입력으로 224 x 224 x 3 의 이미지를 사용하지만 숫자를 살펴보면 227 x 227 일 때 좀 더 그럴듯한 숫자가 됩니다.
첫 번째 층에서는 96 개의 11 x 11 필터를 사용하고 4 의 스트라이드를 이용 -> 55 x 55 x 96 3 x 3 의 크기와 2 의 스트라이드인 최대 풀링을 적용 -> 27 x 27 x 96 5 x 5 의 동일 합성곱 연산 -> 27 x 27 x 256 또 한 번 최대 풀링을 적용 -> 13 x 13 x 256 동일 합성곱을 적용 -> 13 x 13 x 384 3 x 3 의 동일 합성곱 -> 13 x 13 x 384 3 x 3 합성곱을 하면 -> 13 x 13 x 256 최대 풀링을 적용 -> 6 x 6 x 256 = 9216 이것을 전개해서 9216 개의 노드로 만들면 완전 연결 층을 가지게 되고 소프트맥스를 사용해서 가능한 1,000 개의 출력을 나타내게 됩니다.
<LeNet과 차이점> 이 신경망은 LeNet 과 매우 유사하지만 훨씬 큰 크기를 가집니다 LeNet 이나 LeNet-5 는 6만 개 정도의 매개 변수를 가졌지만 AlexNet 의 경우는 6천만 개 정도의 매개 변수를 가지죠. 더 많은 은닉 유닛과 더 많은 데이터를 통해 훈련하기 때문에 훨씬 더 뛰어난 성능을 보여줄 수 있는 것입니다 이 구조가 LeNet 과 구별되는 또 다른 하나의 특성은 ReLU 활성화 함수를 사용한다는 것입니다
VGG - 16 의 주목할 만한 점은 많은 하이퍼 파라미터를 가지는 대신 합성곱에서 스트라이드가 1 인 3 x 3 필터만을 사용해 동일합성곱 최대 풀링층에서는 2 의 스트라이드의 2 x 2 를 사용합니다
이미지에서 시작해서 첫 두 층에서는 64 개의 필터를 사용해 합성곱 -> 224 x 224 x 64 (2개) 풀링층 -> 112 x 112 x 64 128 개의 필터를 가진 동일 합성곱 -> 112 x 112 x 128 풀링층 -> 56 x 56 x 128 256 개의 필터의 합성곱층 3 개 풀링층 그리고 몇 개의 합성곱층과 풀링층을 번갈아가며 사용하면 결국에는 7 x 7 x 512 의 완전 연결층이 됩니다 4096 개의 유닛과 1000 개의 소프트맥스 출력이 나오게 되죠
VGG - 16 의 16 이라는 숫자가 의미하는 것은 16 개의 가중치를 가진 층이 있다는 것입니다. 1억 3천 8백만 개 정도의 변수를 가진 상당히 큰 네트워크 입니다. 그리고 합성곱층의 필터의 개수를 한 번 살펴보면 64 가 128, 256, 512 로 두 배씩 늘어납니다 그래서 이 구조의 상대적인 획일성이 가지는 단점은 훈련시킬 변수의 개수가 많아 네트워크의 크기가 커진다는 것입니다.
그리고 문헌을 읽다보면 보이는 VGG- 19 은 이것보다 더 큰 버전이죠
3. ResNets
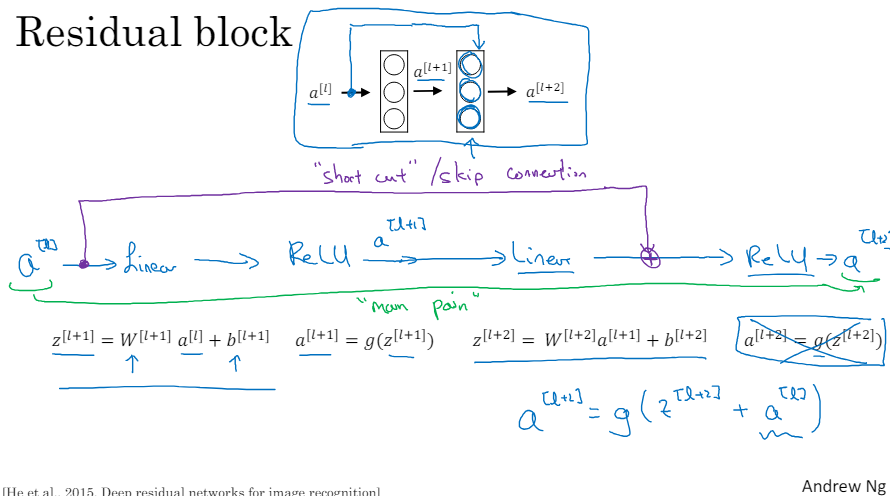
스킵 연결 : 한 층의 활성값을 가지고 훨씬 깊은 층에 적용하는 방식 이것을 통해서 ResNet 을 형성할 수 있습니다.
ResNet의 잔여 블록 신경망의 두 층이 있습니다 활성값 a^[l] 에서 시작해서 a^[l+1] 으로 가고 두 층이 지난 뒤 활성값은 a^[l+2] 입니다. 이 계산 과정을 한 번 살펴보면 a^[l] 에 선형 연산자를 적용해 줍니다. a^[l] 에서 z^[l+1] 을 계산하기 위해서는 가중치 행렬을 곱해주고 편향 백터를 더해줍니다. 그 뒤에는 ReLU 비선형성을 적용해 a^[l+1] 을 계산합니다. a^[l+1] = g(z^[l+1]) 그 다음 층에서는 또 선형 연산을 적용해주고 ReLU 연산을 적용해줍니다. g 가 ReLU 비선형성이죠. 그리고 이것으로 a^[l+2] 를 얻습니다 다시 말해 a^[l] 의 정보가 a^[l+2] 로 흐르기 위해서는 이 모든 과정을 거쳐야 합니다. 이것을 여러 층의 "main path" 라 부르고 ResNet 에서는 이것을 조금 바꿔서 a^[l] 을 복제해서 신경망의 더 먼 곳까지 단번에 가게 만든 뒤 ReLU 비선형성을 적용해주기 전에 a^[l] 을 더해주고 이것을 "short cut" 이라고 부를 겁니다. 그러면 "main path" 를 따르는 대신 a^[l] 의 정보는 "short cut" 을 따라서 신경망의 더 깊은 곳으로 갈 수 있겠죠. 이것으로 마지막 식이 필요가 없어지고 대신 a^[l+2] = g(z^[l+2] + a^[l] ) 이 됩니다. a^[l] 은 잔여 블록이 됩니다. 위에 있는 그림에서도 지름길을 그려주면 되죠.
두 번째 층으로 가는 이유는 ReLU 전에 더해지기 때문입니다. 여기 각 노드들은 선형 연산과 ReLU 를 적용하는데 a^[l] 은 선형 연산 뒤에 삽입되고 ReLU 연산 전에 들어갑니다. 그리고 "short cut" 대신 스킵 연결이라는 표현을 사용하기도 하는데 a^[l] 이 정보를 전달하기 위해 층을 뛰어넘는 걸 의미합니다. 잔여 블록을 사용하면 훨씬 깊은 신경망을 훈련시킬 수 있습니다. 그래서 ResNet 을 구축하는 방법은 이러한 잔여 블록들을 쌓아서 깊은 신경망을 만드는 것입니다.
위 네트워크는 ResNet 논문의 표현으로는 평형망이라고 불립니다. 이것을 ResNet 으로 바꾸려면 스킵 연결을 더해주면 됩니다. 그래서 두 층 마다 잔여 블록으로 만들어 줍니다. 이 그림은 다섯 개의 잔여 블록이 합쳐진 것이고 이것이 ResNet 입니다.
만약 표준 최적화 알고리즘을 사용한다면 경사 하강법이나 다른 멋진 최적화 알고리즘을 사용해 평형망을 훈련시킵니다. 층의 개수를 늘릴 수록 훈련 오류는 감소하다가 다시 증가합니다. 이론 상으로는 깊은 신경망이 도움이 되지만 실제로는 평형망의 깊이가 매우 깊다면 최적화 알고리즘으로 훈련을 하는 것이 더 어려워질 것이고 너무 깊은 신경망을 선택하면 훈련 오류는 더 많아집니다. 하지만 ResNet 에서는 층이 깊어져도 훈련 오류가 계속 감소하는 성능을 가질 수 있습니다.
4. 왜 ResNets 이 잘 작동할까요?
왜 ResNet 이 효과적인가?
X 를 하나의 거대한 신경망에 투입해서 a^[l] 이라는 활성값을 출력한다고 해봅시다.
아래 예시에서는 그 신경망을 좀 더 깊게 만들어볼텐데 동일한 신경망이 있고 a^[l] 을 출력한 다음 이 네트워크에 몇 개의 층을 추가해줄 것입니다. 하나의 층을 더하고 또 다른 층을 더해주면 a^[l + 2] 가 나오게 되죠. 그리고 지름길을 추가해 잔차 블록으로 만들어 줍니다. 변수의 측면에서 보았을 때 신경망 전반에 걸쳐서 ReLU 활성화 함수를 사용하기 때문에 입력값인 X 를 제외하고는 모든 활성값이 0 보다 크거나 같죠.
a^[l + 2] 가 어떤 것일지 한 번 살펴보면 이전 영상에서 a^[l + 2] 는 (z^[l + 2]+ a^[l]) 에 ReLU 를 적용한 것이었습니다. 여기 더해진 a^[l] 이 뜻하는것은 좀 전에 추가한 스킵 연결이고 이 식을 전개하게 되면 g(w^[l + 2] a^[l]) + b^[l + 2] + a^[l]) 에서 "w^[l + 2] a^[l]) + b^[l + 2]" 이 부분에 a^[l] 을 더해주는데 한 가지 짚을 점은 만약 L2 규제나 가중치 붕괴를 사용하면 w^[l + 2] 의 값이 감소합니다. 만약 가중치 붕괴를 b 에 적용해도 마찬가지로 감소하죠 w^[l + 2] 가 0 이고 b 도 마찬가지로 0 이라면 g(a^[l]) 은 a^[l] 과 같습니다 (ReLU 활성화 함수를 사용해서 모든 활성값이 양수기 때문) 그래서 항등 함수는 잔여 블록의 훈련을 용이하게 만들어 줍니다. 그리고 a^[l + 2] 가 a^[l] 과 같게 되는 이유는 스킵 연결때문입니다
이것이 의미하는 바는 신경망에 이 두 층을 추가해도 두 층이 없는 더 간단한 네트워크만큼의 성능을 가지는 이유가 항등 함수를 학습하여 a^[l + 2] 에 a^[l] 을 대입하면 되기 때문인 것입니다.
ResNet에서는 F(x[l])를 0으로 만들어 주기만 하면, 출력은 자동으로 입력과 동일하게 유지됩니다.
이것이 바로 잔차 블록을 거대한 신경망 어딘가에 추가해도 성능에 지장이 없는 이유입니다.
하지만 우리의 목표는 성능에 지장을 주지 않는 정도가 아니라 성능을 향상시키는 것이기 때문에 만약 이 은닉 유닛들이 학습을 할 수 있다면 항등 함수를 학습하는 것보다 더 나은 성능을 보여줄 수 있죠.
스킵 연결 없이 만들어진 아주 깊은 네트워크의 문제는 네트워크를 깊게 만드려고 하면 할수록 변수를 선택하기 어려워집니다. 항등 함수를 학습하는 것이라도 말이죠. 그래서 많은 수의 층이 오히려 성능을 저하시킬 수 있는 것입니다 ResNet 이 잘 작동하는 주된 이유는 추가된 층이 항등 함수를 학습하기 용이하기 때문입니다. 그래서 성능의 저하가 없다는 것을 보장할 수 있고 또는 운이 좋다면 성능을 향상시킬 수도 있는 것이죠
다만, z^[l + 2] 와 a^[l] 이 같은 차원을 가져야합니다. 그래서 ResNet 에서 많이 볼 수 있는 것은 동일 합성곱인데 이곳의 차원이 출력 층의 차원과 같아지게 합니다. 동일 합성곱이 차원을 유지시켜줘서 이러한 단락을 가질 수 있게 되고 또 두 개의 동일한 차원의 벡터의 합을 구할 수 있게 됩니다 입력과 출력의 차원이 다른 경우는 예를 들어 이것이 128 차원이고 z 또는 a^[l + 2] 가 256 차원이라면 하나의 W_s 라는 하나의 행렬을 추가해주는데 W_s 는 256 x 128 의 행렬이라 W_s 와 a^[l] 의 곱은 256 차원이 됩니다 그래서 이 덧셈은 두 개의 256 차원 벡터의 합이죠. W_s 에는 여러 선택지가 있는데 학습된 변수를 가진 행렬일 수도 있고 제로 패딩으로 고정값을 가진 행렬이라서 a^[l] 을 가지고 0 을 채워줘서 256 차원이 되는 것이죠 둘 중 어느 것도 가능합니다
마지막으로 이미지에서 ResNet 을 살펴봅시다 이미지를 입력시키면 여러 개의 합성곱 층이 소프트맥스 출력이 있을 때까지 있는데 이것을 ResNet 으로 바꾸려면 이런 스킵 연결들을 추가해줘야 합니다. 여기 아주 많은 3 x 3 합성곱이 있는데 그 중 대부분은 동일 합성곱입니다. 그래서 같은 차원의 벡터를 더해주는 것이죠. 완전 연결 층이 아닌 합성곱 층이라 할 수 있는데 동일 합성곱이라 차원이 유지됩니다. 그래서 z^[l + 2] + a^[l] 이 성립이 되는 것이죠
전에 봤던 네트워크와 같이 다수의 합성곱 층을 가지고 있고 때때로 풀링 층이나 유사한 것을 가지고 있는데 그런 것이 나올 때마다 차원을 조정해줘야 합니다. 이전 슬라이드에서 봤던 W_s 말이죠.
5. Network 속의 Network
192 개의 입력숫자가 32개의 1 x 1 필터와 합성곱을 하여 32 개의 출력 숫자가 됩니다. 즉, 이는 입력 채널의 수만큼 유닛을 입력으로 받아서, 이들을 하나로 묶는 연산과정 통해, 출력채널의 수만큼 출력을 하는 작은 신경망 네트워크로 간주 할 수 있습니다. 따라서 네트워크 안의 네트워크라고도 합니다.
1x1 합성곱 연산을 통해 비선형성을 하나 더 추가해 복합한 함수를 학습 시킬 수 있고, 채널수를 조절 해줄 수 있습니다.
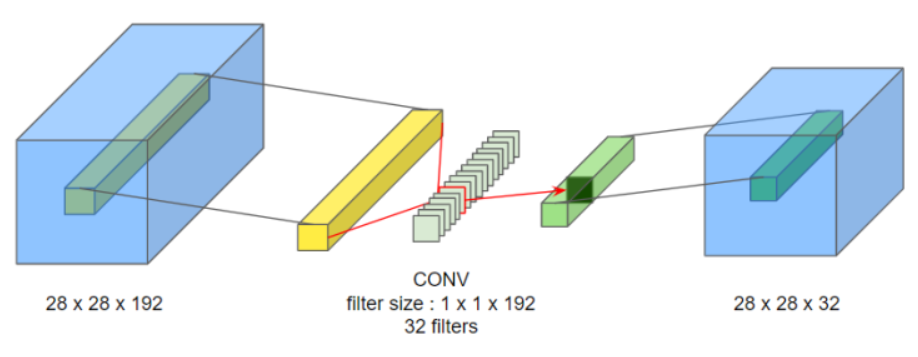
<1 x 1 합성곱이 유용한 경우> 28 x 28 x 192 의 입력이 있다고 해봅시다. 만약 높이와 너비를 줄이려면 풀링 층을 사용하면 됩니다. 그럼 만약 채널의 수가 너무 많아서 줄이려면 어떻게 해야 할까요? 바로 32 개의 1 x 1 필터를 사용하면 됩니다. 실제로는 각 필터가 1 x 1 x 192 의 크기를 가지겠죠. 필터와 입력의 채널 수가 일치해야 하기 때문입니다
6. Inception 네트워크의 아이디어
인셉션 네트워크
: 필터의 크기나 풀링을 결정하는 대신 전부다 적용해서 출력들을 합친뒤 네트워크로 하려금 스스로 변수나 필터 크기의 조합을 학습하게 만드는 것
위와 같은 인셉션 네트워크의 문제는 계산 비용입니다.
단순 5 x 5 필터만 봐도 필요한곱셈은 출력 크기(28 x 28 x 32) x 각 필터(5 x 5 x 192) = 약 1억 2000 만개 입니다.
하지만 이를 1 x 1 합성 곱으로 해결 할 수 있습니다.
계산 비용 해결방안: 1 x 1 합성곱
5 x 5 합성곱을 사용하기 전에 1 x 1 의 합성곱 연산을 통해 입력 이미지의 볼륨을 줄이는 작업을 합니다. 그 후에 다시 5 x 5 합성곱 연산을 하는데, 이때 계산 비용은 약 1240 만개로 아래와 같습니다.
1 x 1 합성곱: 28 x 28 x 16 x 1 x 1 x 192 = 약 240 만개
5 x 5 합성곱: 28 x 28 x 32 x 5 x 5 x 16 = 약 1000 만개
학습에 필요한 계산 비용이 1/10 수준으로 크게 줄어든 것을 알 수 있습니다. 여기서 사용된 1 x 1 합성곱 층을 “병목 층”이라고도 합니다.
병목층을 사용시 표현의 크기가 줄어들어 성능에 영향을 지장을 줄지 걱정 될 수도 있는데, 적절하게 구현시 표현의 크기를 줄임과 동시에 성능에 큰 지장 없이 많은 수의 계산을 줄일수 있습니다.
7.Inception 네트워크
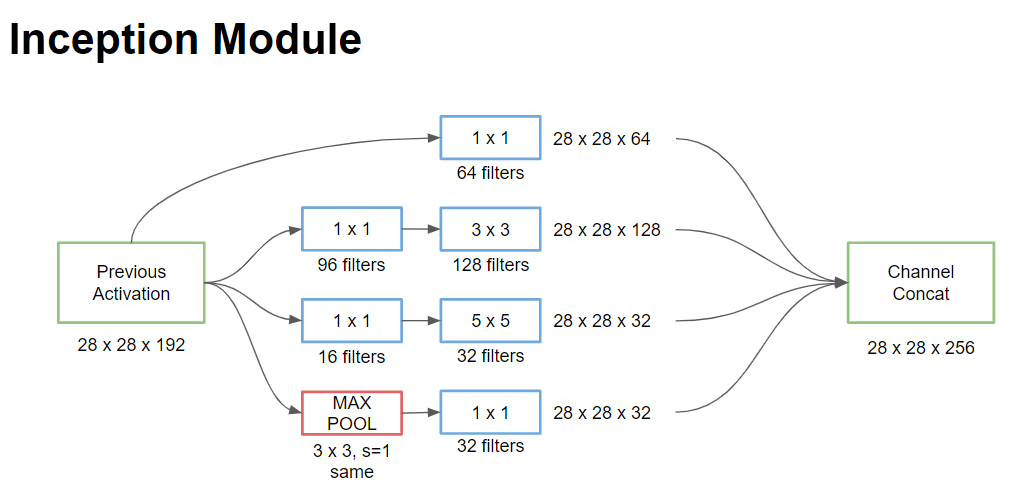
인셉션 네트워크는 위 그림과 같이 여러개의 인셉션 모듈로 구성 되어있습니다.
인셉션 모듈은 활성값이나 이전 층의 출력을 입력값으로 받습니다 입력값을 28 x 28 x 192 라고 해봅시다. 우리가 살펴본 예시는 1 x 1 과 5 x 5 의 층을 사용한 것인데 1 x 1 의 경우에는 16 개의 채널이 있었고 5 x 5 의 경우에는 28 x 28 x 32 의 출력 크기를 가졌습니다. 3 x 3 합성곱의 계산을 줄이기 위해 동일한 것을 수행할 수 있습니다. 이 경우에는 28 x 28 x 128 의 출력이 있겠죠. 1 x 1 합성곱에는 또 다른 1 x 1 합성곱이 필요하지는 않습니다. 출력으로는 28 x 28 x 64 가 나옵니다. 마지막으로는 풀링 층이 있습니다. 이 결과들을 엮어주기 위해서 풀링에 동일 패딩을 적용해서 높이와 너비가 28 x 28 로 유지되어서 다른 결과와 엮을 수 있게 됩니다. 하지만 동일 패딩을 가진 최대 풀링을 사용한다면 3 x 3 필터에 스트라이드를 1 로 놓는다면 그 결과는 28 x 28 x 192 의 크기를 가집니다. 입력과 동일한 수의 채널을 가지게 되죠. 딱 보기에 채널이 너무 많아 보입니다. 그래서 여기 1 x 1 의 합성곱 층을 추가해줘서 채널의 수를 줄여서 28 x 28 x 32 로 만드는 것이죠. 그러기 위해서는 32 개의 1 x 1 x 192 필터가 필요합니다. 그래서 출력의 채널 수가 32 로 줄어드는 것이죠.
마지막으로 이 블록들을 모아서 연결해 줍니다. 64 + 128 + 32 + 32 개를 하나로 연결하게 되면 28 x 28 x 256 크기가 됩니다. 채널 연결은 이전 영상에서 본 블록들을 연결해주는 것입니다. 이것이 하나의 인셉션 모듈입니다
인셉션 모델 구조
중간 중간에 차원을 바꾸기 위한 최대 풀링층을 포함해서 여러개의 인셉션 블록이 계속 반복 되는 것을 볼 수 있습니다.
인셉션 네트워크는 “GoogLeNet ”이라고도 합니다.
인셉션 네트워크는 이런 모듈들을 하나로 모아놓은 것이죠. 인셉션 블록들이 있고 여기에는 차원을 바꾸기 위한 최대 풀링층이 추가적으로 있습니다. 원래의 논문을 읽으면 인셉션 네트워크에 대한 또 다른 점이 있는데 이러한 곁가지들이 있다는 것입니다. 네트워크의 마지막 몇 개의 층은 완전 연결 층이고 그 뒤에는 예측을 위한 소프트맥스 층이 있는데 이 곁가지가 하는 일은 은닉 층을 가지고 예측을 하는 것입니다. 그래서 이 부분이 소프트맥스죠. 그리고 또 다른 곁가지도 은닉층을 가지고 완전 연결 층을 지나서 소프트맥스로 결과를 예측합니다.
이것을 인셉션 네트워크의 또 다른 세부 사항이라 할 수 있지만 은닉층이나 중간 층에서 계산된 특성들이라도 이미지의 결과를 예측하는데 아주 나쁘지는 않다는 것입니다. 인셉션 네트워크에 정규화 효과를 주고 네트워크의 과대적합을 방지해 줍니다.
정리하자면 인셉션 모듈을 이해하면 인셉션 네트워크를 이해할 수 있습니다. 인셉션 모듈이 네트워크 상에서 반복되는 것이기 때문이죠. 이후에 나온 인셉션 v2, 인셉션 v3, 인셉션 v4 등을 사용하는 것도 볼 수 있습니다. 그리고 그 중 하나는 ResNet의 스킵 연결을 활용하는데 훨씬 더 나은 성능을 보여줍니다. 하지만 그 모든 것들이 이번에 배운 것에 기초를 두고 있습니다. 다수의 인셉션 모듈을 모아서 쌓는 개념 말이죠.