[boostcourse] 1. 컴퓨터 비전의 시작
Computer Vision이란?
컴퓨터 비전 : 시각 지각 능력을 컴퓨터 시스템으로 구현하는 것

- 이미지에서 정보를 해석해내는 것 : Computer Vision (Inverse rendering)
- 정보를 통해서 이미지를 구현해내는 것 : Computer Graphics (Rendering)
컴퓨터비전은 machine visual perception을 만드는 것이다.
입력은 영상이나 비디오같은 visual data이다.
컴퓨터비전은 사람의 biological한 특징을 이해하고 이것을 알고리즘으로 구현하는 것까지 포함한다.

과거에는 사람이 직접 feature를 추출했다. 추출된 특징들과 해결하고자 하는 목표 task 사이의 관계를 간단한 모델을 통해 학습하는 방식으로 컴퓨터 비전이 구현되었다.

딥러닝을 활용하면 사람이 직접 특징을 추출해줄 필요없이 입출력 쌍만 주어지면 End-to-end로 학습한다.
gradient descent가 이 과정을 대신한다.
Image Classification (1) : 개념
Classifier

- 입력 : 이미지
- 출력 : 분류되는 카테고리
모든 데이터를 가지고있다면 k-NN에 의해 해결될 수 있다.
k Nearest Neighbors (k-NN) 이란?

쿼리 데이터에 인접한 k개의 이웃 데이터를 찾고 그 데이터들이 가지고 있던 라벨 정보를 기반으로 해서 분류한다.

하지만 이세상의 모든 데이터를 담기는 불가능하다.
또한 이미지간의 유사도를 정의하는 것도 쉽지 않다.

데이터를 뉴럴 네트워크 파라미터에 녹여넣는다!
Single-layer Neural Network

이렇게 간단한 모델이 잘 작동하지 않는 이유?
1. 클래스의 평균적인 이미지와 동떨어져있는 이미지의 경우 잘 표현되지 않는다
2. Test time에서의 성능이 매우 떨어질 수 있다 (조금이라도 이미지가 달라지면 성능이 떨어진다)
Convolutional Neural Network (CNN)

FC layer - 특징을 뽑기 위해 모든 픽셀을 고려한다.
CNN - 국부적인 영역의 특징을 뽑아낸다.
-> 계산해야하는 파라미터가 줄어든다.
-> 지역적인 특징을 추출하기 때문에 이전에 예시를 들었던 crop된 말 이미지를 입력하더라도 올바르게 분류할 수 있다.
-> 따라서 많은 CV task의 backbone 네트워크로 많이 활용된다.
CNN의 경우 파라미터 수
전체 파라미터 수 = (각 필터의 파라미터 수) * (필터의 총 개수) = 100 * 10,000 = 1,000,000
CNN을 활용한 image classification

LeNet-5

- 이때의 구조는 conv층 2개, FC 2개로 구성된 간단한 구조였다.
- 주로 하나의 글자를 인식하는데 사용되었다.
AlexNet

- LeNet-5에서 motivation을 따왔다.
- 7개의 layer로 층이 깊어졌다. 파라미터가 많아졌다. 학습에 사용한 데이터도 많아졌다(ImageNet)
- ReLU 활성화함수를 사용했다.
- 네트워크 path가 2개로 나뉘어져 있다. -> GPU 메모리가 작았기 때문
- 중간중간 activation map이 크로스하는 부분 -> 일부에서 GPU 메모리 교환
- 2048부분 주목!
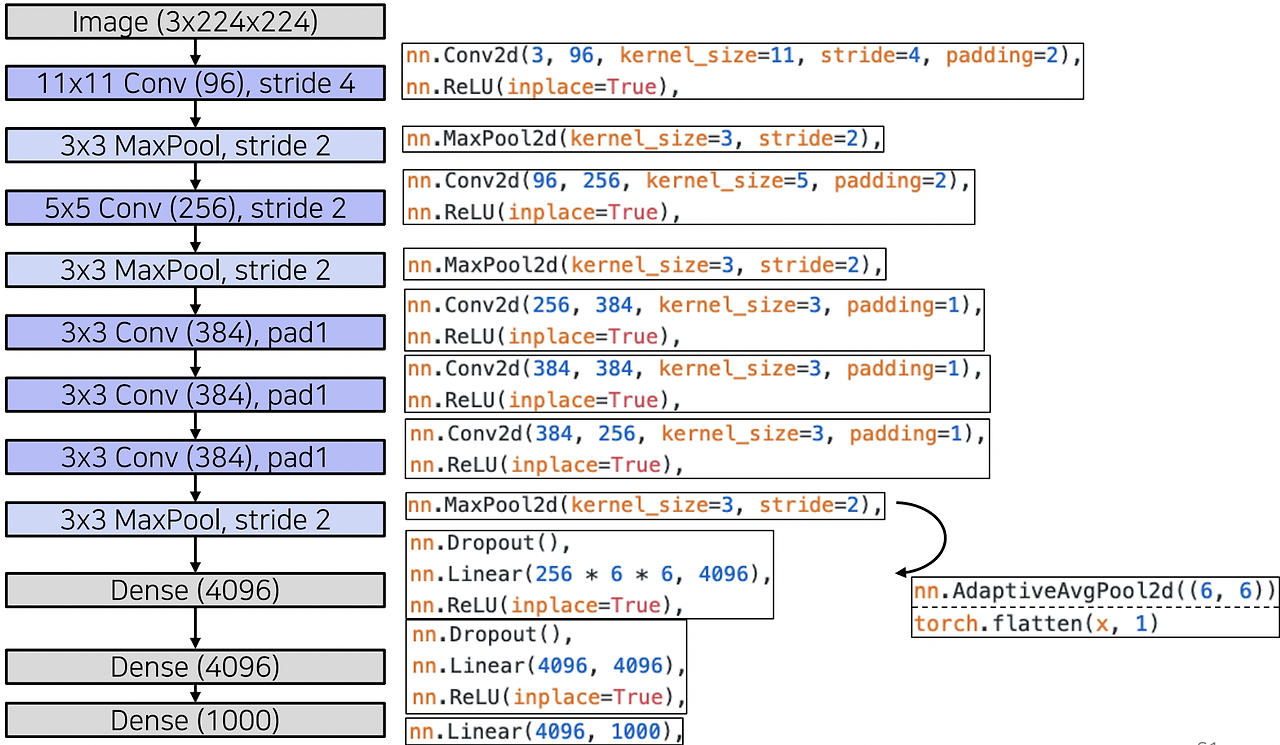
- Conv, ReLU, MaxPool 의 반복
- MaxPool된 2D 맵이 Linear층으로 가기 위해선 벡터화를 거쳐야 한다. (3D 텐서 형태 -> 2D 벡터 형태)
- 벡터화되는 2가지 방법 - Average Pooling, Flatten
- Average Pooling : 텐서의 공간 정보를 다 압축시켜서 채널축의 정보만 남겨둔 벡터로 만든다.
- Flatten : 텐서를 순서에 따라 나열해서 벡터로 쌓는다.
- AlexNet에서는 flatten이 사용되었다.
- 2048에서 4096이 되었다. -> 그 당시에 GPU 용량 부족으로 절반씩 학습했다.
- LRN -> 현재는 잘 사용되지 않는다. normalization의 역할. -> 현재는 batch normalization으로 사용
- 11 x 11 필터 -> 현재는 큰 필터 사이즈는 잘 사용되지 않는다.

- Receptive field : 특징 추출에 사용하는 input space에서의 해당 영역
- 두 layer 사이의 receptive field 공식 : (P + K - 1) x (P + K - 1) P : 풀링층 사이즈, K : 커널 사이즈
VGGNet

- 16개, 19개의 층을 가진다.
- 간단한 구조를 가지며 3 x 3, 2 x 2의 풀링만 쌓는다. -> 작은 layer들도 많이 쌓으면 큰 receptive field size를 얻는다!
- 더 적은 파라미터를 갖는다.
- 성능이 좋고 일반화가 잘된다.
- AlexNet을 최대한 유지하려 했다.
- train image의 평균 RGB 값들을 각 채널에서 빼주면서 입력으로 넣어주었다. (normalization)
- 마지막 layer는 3개의 FC layer