그림처럼 두 개의 입력 특성이 있는 훈련 세트가 있을 때 두 단계에 따라 입력을 정규화할 수 있다.
첫 번째 과정은 평균을 0으로 만드는 것이다.
뮤는 1/m 곱하기 1부터 m까지 x(i)의 합이고 이 값은 벡터이다. x는 x-뮤로 설정됩니다
이 식은 오른쪽 그래프와 같이 0의 평균을 갖게 될 때까지 훈련 세트를 이동하는 것을 의미한다
두 번째 과정은 분산을 1로 만드는 것이다.
그래프를 보면 특성 x1이 특성 x2보다 더 큰 분산을 갖고 있다.
시그마 제곱은 1/m 곱하기 1부터 m까지 x(i)제곱의 합이고 이 값은 각 특성의 분산에 대한 벡터이다
x는 시그마 제곱분의 x로 설정한다
이 식을 적용하면 x1과 x2의 분산은 이제 1이 된다
교수님께서 몇가지 팁을 주셨는데 이것을 훈련데이터를 확대하는데 사용한다면 테스트 세트를 정규화할 때도 같은 뮤와 시그마를 사용해야 한다. 같은 뮤와 시그마를 사용해야 훈련 세트와 테스트 세트를 같게 정규화할 수 있다.
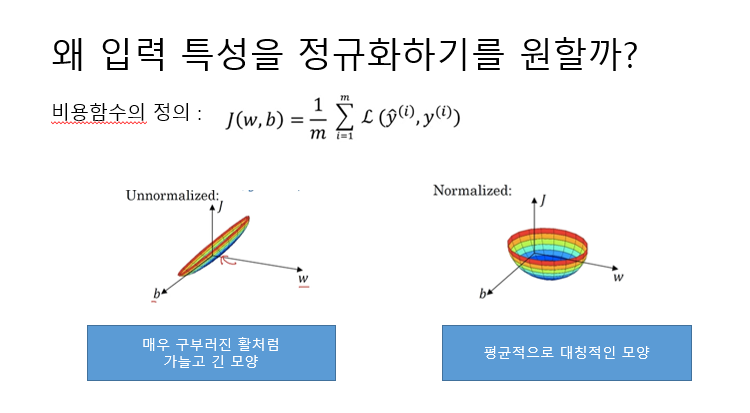
그럼 왜 입력 특성을 정규화하기를 원할까?
비용함수의 정의는 위의 식과 같다. 정규화되지 않은 입력 특성을 사용하면 비용함수는 왼쪽과 같이 매우 구부러진 활처럼 가늘고 긴 모양이 된다. 만약 특성 x1의 범위가 1부터 1000이고 특성 x2의 범위가 0부터 1이라면 매개변수에 대한 비율, 값의 범위는 w1, w2가 굉장히 다른 값을 갖게 된다. 따라서 이처럼 매우 가늘고 긴 모양이 된다.
반면에 정규화된 입력 특성을 사용하면 비용함수는 오른쪽과 같이 평균적으로 대칭적인 모양을 갖게 된다.
함수의 등고선을 보면 왼쪽은 가늘고 긴 함수를 얻는다. 왼쪽 함수의 비용함수에 경사 하강법을 실행한다면 매우 작은 학습률을 사용하게 된다. 따라서 경사 하강법은 최솟값에 이르는 길을 찾기 위해 앞 뒤로 왔다 갔다하는데 많은 단계가 필요하다.
반면에 오른쪽 원 모양의 등고선의 경우 어디서 시작하든 경사 하강법은 최솟값으로 바로 갈 수 있다. 왼쪽처럼 왔다갔다 하지 않아도 큰 스텝으로 전진할 수 있다.
실전에서는 w가 높은 차원인 벡터이고 2차원에 그리는 것이 모든 직관을 올바르게 전달하지 않는다. 그러나 특성이 비슷한 크기를 갖을 때 비용함수가 더 둥글고 최적화하기 쉬운 모습이 된다는 대략적인 직관을 얻을 수 있다.
따라서 평균을 0으로 설정하고 모든 특성이 비슷한 크기가 되도록 분산을 설정하면 학습 알고리즘이 빠르게 실행되는 것을 도울 수 있다.
특성이 비슷한 크기를 갖는다면 이 과정은 중요하지 않다.
2. 경사소실/경사폭발
매우 깊은 신경망을 훈련시킬 때 나타나는 문제점은 경사의 소실과 폭발이다.
그림처럼 매우 깊은 신경망을 훈련시키는 경우를 생각해보면 이 신경망은 매개변수 w^[1], w^[2], w^[3],...,w^[L]을 갖는다. 간단함을 위해 활성화 함수 g(z)가 선형 활성화 함수를 사용하고 b^[l]은 0이라고 가정해보자. 이 경우 출력 y는 w^[L] 곱하기 w^[L-1] 곱하기 w^[1] 곱하기 x 가 된다.
이때 b^[1]=0이기 때문에 w^[1]x는 z^[1]이 된다. a^[1] = g(z^[1]) 과 같은데 선형함수이기 때문에 이 값은 z^[1]과 같다. 따라서 z^[1]은 결국 a^[1]과 같다.
같은 방법으로 w^[2]w^[1] x는 a^[2]와 같고 w^[3]w^[2]w^[1]x는 a^[3]과 같다.
w^[l]이 1.5 0 0 1.5를 갖는 행렬이라고 했을 때
각각의 행렬이 이 행렬과 같다고 가정하면 y의 예측값은 다른 차원을 갖는 마지막 가중치 행렬 곱하기 이 행렬의 L-1 제곱 곱하기 x가 된다. 이때 이 행렬은 1.5 곱하기 단위 행렬이기 때문에 y의 예측값을 다음과 같이 나타낼 수 있다. 더 깊은 신경망일수록 y hat의 값은 기하급수적으로 커진다.
반대로 모든 가중치 행렬이 0.5 곱하기 단위 행렬이라고 가정하면 y hat은 다음과 같고 더 깊은 신경망일수록 y hat의 값은 기하급수적으로 감소한다.
따라서 경사 하강법에서 w의 값이 단위행렬보다 큰 값이라면 경사의 폭발, w 의 값이 단위 행렬보다 작은 값이라면 경사 소실의 문제점이 생긴다.
현대의 신경망은 L이 150의 값을 갖는데 마이크로소프트는 최근 852개의 층을 가진 신경망을 내놓았다. 이런 깊은 신경망에서 활성값이나 경사가 L에 대한 함수로 기하급수적으로 증가하거나 감소한다면 값들은 아주 커지거나 작아질 수 있기 때문에 훈련을 시키는 것이 어려워진다.
3. 심층 신경망의 가중치 초기화
이 문제는 가중치를 어떻게 초기화시키느냐에 따라 해결할 수 있다.
먼저 하나의 뉴런이 있는 예제를 살펴보면 이 뉴런은 하나의 뉴런에 특성 4개가 입력되고 a는 g(z) 이다. b의 값을 무시하면 z = w1x1 + w2x2+ ... + wnxn 이다. z의 값이 너무 크거나 작아지지 않도록 만들어야 한다. 따라서 z는 wixi의 합이기 때문에 많은 항들을 더하면 각각의 항이 작아져야 해서 n의 값이 클수록 wi의 값이 작아져야 한다.
첫 번째 방법은 wi의 분산을 1/n로 설정하는 것이다. 이때 n은 입력 특성의 개수이다.
따라서 실제로 특정 층에 대한 가중치 행렬 w^[l]을 np.random.randn에 집어넣는다. 이 값에 층 l의 뉴런에 들어가는 특성의 개수의 역수를 곱한다.
n^[l-1]을 사용하는 이유는 이 예제의 로지스틱 회귀에서는 n개의 입력 특성을 갖지만 더 일반적인 경우에 층 l을 해당 층의 각 유닛에 대해 n^[l-1]의 입력을 갖기 때문이다.
tanh 활성화 함수를 사용하는 경우 wi의 분산을 1/n^[l-1] 또는 2/n^[l-1]+n^[l]으로 설정한다. 더 일반적으로 사용되는 것은 1/n^[l-1] 라고 한다.
이런 방법들은 각각의 가중치 행렬 w를 1보다 너무 커지거나 너무 작아지지 않게 설정해서 너무 빨리 폭발하거나 소실되지 않게 한다. 하지만 식들은 가중치 행렬의 초기화 분산에 대한 기본 값을 제공할 뿐이기 때문에 분산 매개변수를 하이퍼파라미터로 조정하는 과정을 거쳐야 한다.
4. 기울기의 수치 근사
역전파를 구현할 때 경사 검사라는 테스트가 있는데 경사 검사를 통해 역전파를 알맞게 구현했는지 확인할 수 있다. 경사 검사를 구현하기 위해 경사의 계산을 수치적으로 근사하는 방법을 알아보겠다.
f가 세타 세제곱이라고 할 때 θ = 1인 경우 입실론은 0.01, θ+ϵ = 1.01, θ-ϵ = 0.99 이다.
양쪽의 차이를 이용해 큰 삼각형을 이용하면 도함수를 근사하는데 더 나은 값을 이용할 수 있다. 삼각형의 너비 분의 높이는 ~이고 이 값은 g(세타)와 비슷해야 한다.
값을 대입하기 위해 f(θ) = θ^3을 이용하여 값을 계산하면 3.0001을 얻게 된다.
g(세타)는 3곱하기 세타 제곱이고 세타가 1일 때 이 값은 3이기 때문에 근사 오차는 0.0001 이다.
한 쪽의 차이만을 이용하여 같은 계산을 하면 근사 오차는 0.03으로 더 크다.
따라서 도함수를 근사하기 위해 양 쪽의 차이를 이용하는 것이 더 정확하다는 것을 알 수 있다.
한 쪽의 차이만을 사용하는 것보다 두 배는 느리게 실행되지만 훨씬 더 정확하다.
5. 경사 검사
경사 검사 : 모델의 가중치에 대한 손실 함수의 기울기(gradient)를 계산하는 과정이다.
모델의 가중치를 조정하여 손실 함수를 최소화하는 방향으로 모델을 학습시키는데 사용한다.
경사 검사는 시간을 절약하고 역전파의 구현에 대한 버그를 찾는데 도움을 준다.
신경망이 매개변수 W^[1], b^[1]부터 W^[L], b^[L]까지 가지고 있을 때 경사 검사를 위한 첫 번째는 매개변수들을 하나의 큰 벡터 세타로 바꾸는 것이다.
행렬 W^[1]을 벡터로 크기를 바꾸고 모든 W행렬을 받아서 벡터로 바꾸고 모두 연결시키면 매우 큰 벡터 매개변수 θ를 얻게 된다. 비용 함수는 J(W, b) 에서 J( θ ) 로 변한다.
W와 b에서 했던 것과 같은 순서로 dW^[1], db^[1] 의 매개변수를 하나의 벡터 dθ로 만든다. dW^[1]을 벡터로 바꾸고 db^[1]은 이미 벡터이다. 모든 dW행렬을 받아서 벡터로 바꾸고 모두 연결시키면 매우 큰 벡터 dθ를 얻게 된다. 이때 dθ는 θ와 같은 차원을 갖는다.
여기서 질문은 dθ가 비용함수 J( θ )의 기울기인가?이다.
경사 검사를 구현하기 위해 gradient checking을 사용할 수 있다.
Gradient checking : 딥러닝 모델에서 수치적 경사도와 분석적 경사도의 일치 여부를 확인하는 것
J는 이제 매우 큰 매개변수θ에 관한 함수이고 J( θ )를 J( θ1, θ2, θ3, ... )로 확장시켜도 된다.
경사 검사를 구현하기 위해 반복문을 작성하면 θ의 요소 각각에 대하여 dθapprox[i]는 양쪽 차이를 이용해 θi에만 입실론을 더하고 빼 다음과 같이 구현할 수 있다. dθ[i]가 비용함수 J의 도함수라면 이 값은 함수 J의 θi에 대한 편미분인 dθ[i]와 근사적으로 같아야 한다.
두 벡터가 근사적으로 같은지 확인하려면 두 벡터가 꽤 가까운지 보면 되는데 이때유클리디안 거리를 사용한다. 보통 거리가10^−7승보다 작으면잘 계산되었다고 판단한다. 10^-3보다 큰 값이면 버그가 너무 크니 θ의 개별적인 원소를 신중하게 살펴서 특정 i에 대해 dθapprox[i]와 dθ[i]의 차이가 심한 값을 추적해서 미분의 계산이 옳지 않은 곳이 있는지 확인해야 한다.
1. 수치적 경사도 계산 (Numerical Gradient) 아주 작은 변화 (𝜖ϵ)를 적용하여 손실 함수의 변화를 계산한다. 수치적 경사도는 다음과 같이 계산된다 2. 분석적 경사도 계산 (Analytical Gradient) 역전파 알고리즘을 사용하여 계산된 경사도이다.
3. 비교 수치적 경사도와 분석적 경사도를 비교하여 차이가 매우 작은지 확인한다. 차이가 클 경우, 역전파 알고리즘에 오류가 있을 가능성이 크다.
6. 경사 검사 시 주의할 점
경사 검사 시 주의할 점에 대해 알아보겠다.
1) 훈련에서 경사 검사를 사용하지 말고 디버깅을 위해서만 사용해야 한다.
모든 dθapprox[i]를 계산하는 것은 매우 느리기 때문에 디버깅할때만 이용하고 과정이 끝나면 경사 검사를 끄고 모든 반복마다 실행되지 않도록 한다.
2) 알고리즘이 경사 검사에 실패 했다면, 어느 원소 부분에서 실패했는지 찾아봐야 한다.
dθapprox가 dθ에서 매우 먼 경우 서로 다른 I에 대하여 어떤 dθapprox[i]의 값이 dθ[i]의 값과 매우 다른지 확인해야 한다.
3) 경사 검사를 할 때 사용하는 정규화 항을 기억해야 한다.
비용함수 J( θ ) = 1/m * (손실함수의 합) + 정규화 항과 같다. dθ는 θ에 대응하는 J의 경사로 정규화 항을 포함한다.
4) 경사 검사는 드롭아웃에서는 작동하지 않는다.
드롭아웃은 모든 반복마다 은닉 유닛의 서로 다른 부분집합을 무작위로 삭제하기 때문에 적용하기 쉽지 않다. 따라서 추천하는 방법은 드롭아웃을 끄고 알고리즘이 최소한 드롭아웃 없이 맞는지 확인하고, 다시 드롭아웃을 키는 것이다.
5) 거의 일어나지 않지만 가끔 무작위 초기화를 해도 초기에 가까울 때 경사 검사가 잘 되는 경우가 있다.
이때는 무작위적인 초기화에서 경사 검사를 실행하고 네트워크를 잠시 동안 훈련해서 w와 b가 0에서 멀어질 수 있는 시간을 주어 일정 수의 반복을 훈련한 뒤에 경사 검사를 한번 더 실행시킨다.
경사 검사가 필요한 이유? 1. 역전파 구현 오류 감지 2. 수치적 안정성 확보 3. 모델의 올바른 학습 보장 4. 디버깅 도구
경사 검사는 특히 초기 모델 개발 단계에서 매우 중요하다. 모델이 안정적으로 작동하는 것을 확인한 후에는 매 훈련 과정마다 수행할 필요는 없지만, 모델 구조나 손실 함수에 변화를 주었을 때는 다시 수행하는 것이 좋다.