지금까지 우리가 봤던 분류 문제는 이진 분류였습니다. 0과 1의 두 가지 선택이 있었죠. 고양이냐 아니냐처럼 말이에요. 여러 개의 선택지가 주어진다면 어떨까요?
로지스틱 회귀을 일반화한 소프트맥스 회귀가 있는데요. 이걸 여러 클래스나 C 중 하나를 인식할 때 예측에 사용할 수 있습니다. 클래스가 두 개인 경우 밖에 말이죠. 살펴봅시다. 고양이를 인식하는 것에서 나아가 개, 고양이, 병아리를 인식해봅시다. 고양이는 클래스 1, 개는 클래스 2, 병아리는 클래스 3입니다. 그리고 여기에 해당하지 않는 경우 클래스 0이라고 하죠. 여기에 이미지와 속해 있는 클래스를 적어뒀습니다. 여기에서 대문자 C는 클래스의 숫자를 나타내는 데 사용할 겁니다. 여러분의 입력값을 분류하는 것이죠? 지금은 총 4가지 클래스가 있습니다. 아무 것도 아닌 경우를 포함해서요. 만약 클래스에 숫자를 붙인다면 0에서 C-1까지 부여가 될 겁니다. 여기서는 0, 1, 2, 3이죠.
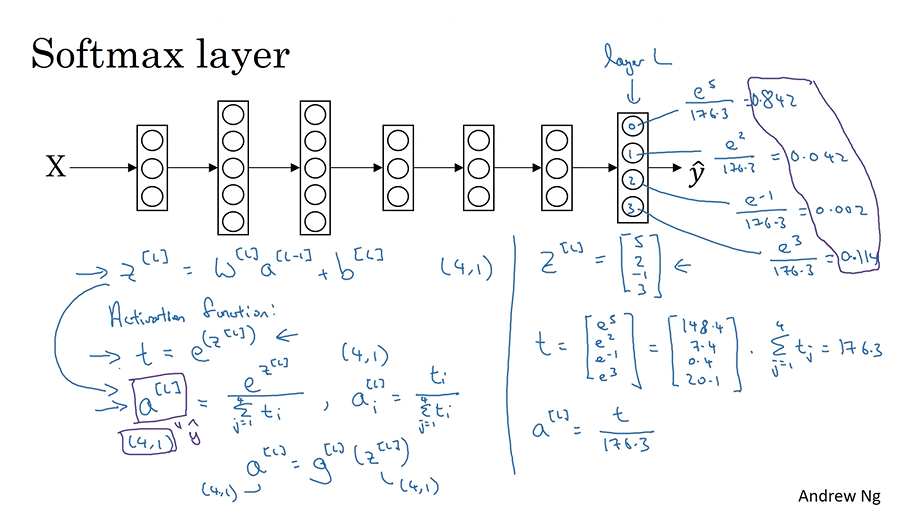
이제 이런 신경망을 하나 만들었다고 합시다. 출력층에는 C개, 이 경우 4개의 출력 단위가 있는 신경망을요. 출력층 L의 단위 개수인 n은 4, 또는 일반적으로 C가 될 겁니다. 우리는 각 단위와 상위층에서 각 클래스의 확률을 알려줬으면 합니다. 첫 번째 단위에서는 우리가 원하는 출력값이 입력값 X가 주어졌을 때 기타 클래스가 나올 확률이겠죠? 여기는 X가 주어졌을 때 고양이의 확률일 테고요. 여기는 X가 주어졌을 때 개의 확률. 여기는 X가 주어졌을 때 병아리의 확률입니다. 병아리를 BC로 줄여쓰도록 하죠. 따라서 출력값인 y^은 (4, 1)차원의 벡터가 될 겁니다. 왜냐하면 출력값으로 네 개의 확률값이 주어질 테니까요. 그리고 y^의 각 값들의 합은 1이 되어야할 겁니다. 이런 신경망을 얻기 위한 가장 표준적인 모델은 출력층에 이런 출력값을 만들 수 있도록 소프트맥스층을 사용하는 겁니다. 큰 그림을 그린 뒤에 다시 돌아가서 소프트맥스가 뭐하는 건지 살펴보죠.
신경망의 최종층에서 평소처럼 층의 선형적인 부분인 z^[L]을 계산할 겁니다. 최종층인 L의 z값이죠. 평소에는 z^[L]을 w^[L]과 이전 층의 활성화 함수를 곱한 뒤 그 최종층의 편향을 더하여 계산했습니다. 이제 z 값을 계산하기 위해서는 소프트맥스 활성화 함수라는 것을 사용해야 합니다. 소프트맥스 층의 활성함수는 조금 다른데요. 함께 보시죠.
우선 t=e^(z^[L])이라는 임시 변수를 사용합니다. 각 원소에 대해 계산하는 데요. 즉 z^[L]이 (4, 1) 차원의 벡터였잖아요? t는 z^[L]의 각 원소에 e를 취한 것이지요. 결과도 (4, 1)이 될 겁니다. 그러면 출력값인 a^[L]은 벡터 t와 같습니다. 다만 합이 1이 되도록 정규화하죠. 즉 a^[L]은 z^[L]을 j가 1부터 4까지, t_j를 모두 더한 값으로 나눕니다. a^[L]은 (4, 1) 벡터이고, 이 벡터의 i 번째 원소는 a^[L]_i라고 적죠. t_i를 t_i 값들의 합으로 나눈 것과 같겠죠.
(예를 들어 (4,1) 벡터인 z^[L]이 [5, 2, -1, 3]이라고 하죠. 원소별로 e를 취해 t를 구합시다. t는 e의 5승, e의 2승, e의 -1승, e의 3승이 되겠죠? 계산하면 e의 5승은 148.4, e의 2승은 7.4, e의 -1승은 0.4, e의 3승은 20.1이 됩니다. 이제 t에서 a^[L]으로 합이 1이 되도록 정규화시키기 위해서 t의 네 개 값의 합을 구하면 176.3이 됩니다. 이제 a^[L]은 t를 176.3으로 나눈 것이 되겠죠. 즉 예시에서 첫 번째 노드의 값은 e의 5승을 176.3으로 나눈 것이겠죠. 그 값은 0.842입니다. 만약 이런 z 값을 얻었다면 클래스 0이 될 확률이 84.2%인 것이죠. 다음 노드의 출력값은 e 제곱을 176.3으로 나눈 값인 0.042이고, 다음은 e의 -1승을 176.3으로 나눠서 0.02입니다. 끝으로 e의 3승을 저 수로 나눠서 0.114라는 값을 얻을 수 있습니다. 즉 11.4%의 확률로 클래스 3이 되는 것이죠. 이렇게 클래스 0,1,2,3이 될 확률을 구할 수 있습니다. 이 신경망의 출력값 y^과도 같은 a^[L]은 (4,1) 벡터가 되겠고 그 안에는 계산한 이 숫자들이 들어가있겠죠. 이 알고리즘은 z^[L]이라는 벡터를 취해서 합이 1이 되는 네 개의 확률 값을 내놓습니다. )
z^[L]에서 a^[L]으로 되는 과정을 요약하자면, e를 취해서 임시 변수 t를 얻어서 정규화한 이 과정을 소프트맥스 활성화 함수로 요약할 수 있습니다. 즉 a^[L]은 z^[L] 벡터에 활성함수 g^[L]을 적용한 것이죠. 이 활성화 함수 g의 특이한 점은 (4,1) 벡터를 받아서 (4,1) 벡터를 내놓는다는 것입니다.
이전에는 활성함수가 하나의 실수값을 받았습니다. 예를 들어 시그모이드나 Relu 활성화 함수 등은 실수를 받아서 실수를 내놨죠. 소프트맥스 활성화 함수의 특이한 점은 정규화를 하기 위해서 입력값과 출력값이 모두 벡터라는 것입니다.
소프트맥스 분류로 할 수 있는 것을 보여드리기 위해 예를 들어 x_1과 x_2의 입력값이 있다고 가정해봅시다. 이 값들은 곧바로 소프트맥스 층에 들어갑니다. 안에는 서너개의 노드가 있고 출력값은 y^입니다. 이렇게 은닉층이 없는 신경망을 보여드릴 거에요. 여기에서 하는 일은 z^[1]을 w^[1]과 x를 곱한뒤 b^[1]을 더하여 계산하고 출력값 y^이자 a^[1]을 z^[1]에 소프트맥스 활성화 함수를 적용시켜 얻는 것입니다.
은닉층이 없는 신경망에서 소프트맥스 함수가 뭘 하는 지 감을 잡아봅시다. 이 예시에서는 입력값 x_1과 x_2에 대하여 이 결정 기준을 나타내는 C=3의 클래스를 가진 소프트맥스 층을 사용했습니다. 여기서 선형적인 기준에 따라 데이터가 세 개의 클래스로 나뉩니다. 우리가 했던 것은 이 그림처럼 학습 세트를 가져와서 비용 함수와 세 개의 선택지에 따라 분류하는 소프트맥스 함수를 학습시키는 것이죠. 색깔은 소프트맥스 분류 함수에 따라 출력값을 나타낸 것이고, 입력값은 가장 높은 확률의 출력값에 따라 색을 입혔습니다. 선형 기준을 갖고 있는 로지스틱 회귀의 일반적인 형태죠. 하지만 클래스는 0,1 또는 0,1,2가 될 수 있고요.
윗열 가운데는 소프트맥스 분류 함수가 나타낸 또다른 경우인데요. 세 개의 클래스에 따라 데이터를 학습시켰습니다. 윗열 오른쪽은 또 다른 분류이고요. 여기서 얻을 수 있는 직관은 두 클래스 사이의 경계가 선형이라는 것입니다. 따라서 예시를 보시면 노란색과 빨간색 사이에도 선형 경계가 그려져 있고, 보라색과 빨간색, 빨간색과 노란색 사이에도 선형 결정 경계가 그려져있습니다. 하지만 다른 선형 함수를 사용해서 공간을 세 개의 클래스로 나눌 수도 있습니다. 더 많은 클래스를 다룬 예시도 살펴봅시다. 아래 왼쪽 예시는 C=4인 경우네요. 여기에서 소프트맥스가 선형 경계를 그리고 있습니다. 아래 가운데는 C=5인 또다른 예시입니다. 아래 오른쪽은 C=6인 마지막 예시입니다.
이렇게 은닉층이 없을 때 소프트맥스 분류 함수가 하는 일을 살펴봤습니다. 만약 은닉 유닛이 여러 개인, 더 깊은 신경망을 다룬다면 여러 클래스를 분류하기 위해 더 복잡하고 비선형의 경계도 볼 수 있을 겁니다. 이 강의를 통해 신경망에서 소프트맥스 층에 대해서나 소프트맥스 활성함수에 대해 감을 잡았길 바랍니다.
2. Softmax 분류기 훈련시키기
이번 영상에는 소프트맥스 분류에 대해 더 깊이 이해하고 소프트맥스 층을 써서 모델을 학습시키는 법을 배워봅시다.
소프트맥스라는 이름은 하드맥스와 반대되는 뜻을 갖는데요. 하드맥스는 z 벡터를 받아와서 이런 벡터로 대응시키죠. 하드맥스는 z의 원소를 살펴보고 가장 큰 값이 있는 곳에 1을 나머지에는 0을 갖는 벡터로 대응시키는 겁니다. 아주 단호한 느낌이죠? 가장 큰 원소만 1이고 나머지는 0이니까요.
소프트맥스는 반면에 부드러운 느낌으로 z를 확률들로 대응시킵니다. 제가 꼭 보여드리고 싶은 것은 소프트맥스 회귀나 활성화 함수가 두 클래스만 다루는 로지스티 회귀를 일반화했다는 겁니다.
만약 C=2라면, 즉 소프트맥스에서 C가 2라면, 결국 로지스틱 회귀와 같아집니다. 이 영상에서 따로 증명하지는 않을 건데요. 대략 증명의 흐름을 보자면 C=2에서 소프트맥스를 적용했을 때 출력층 a^[L]은 C=2에서 출력값 두 개를 모아둔 거겠죠. 0.842와 0.158이라고 하면요. 이 두 숫자의 합은 항상 1이 됩니다. 이 두 숫자의 합이 항상 1이 되니 둘 다 계산할 필요는 없습니다. 그러면 그 숫자를 계산하는 방식이 로지스틱 회귀가 하나의 출력값을 계산하는 방식과 같습니다. 이게 증명의 흐름이고요. 알아두실 것은 소프트맥스 회귀가 클래스가 둘 이상인 경우 로지스틱 회귀를 일반화한 것이라는 겁니다.
로지스틱 회귀 :이진 분류 문제에서 사용 시그모이드 함수 사용 소프트맥스 회귀 : 다중 클래스 분류 문제에서 사용 소프트맥스 함수 사용 소프트맥스 회귀는 로지스틱 회귀를 다중 클래스 문제로 확장한 방법이다.ㅡ.ㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕㅕ
이제 소프트맥스 출력층을 이용해 신경망을 학습하는 법을 살펴봅시다.
우선 신경망을 학습하기 위해 사용했던 손실 함수를 정의해보죠. 예를 들어 봅시다. 한 샘플이 목표로 하는 출력값이 관측을 기반으로 0, 1, 0, 0이라고 합시다. 지난 영상을 생각해보면 이 벡터는 고양이를 뜻하죠. 클래스 1이니까요. 그리고 우리 신경망의 출력값 y^은 다음과 같다고 합시다. y^은 합이 1인 확률로 구성된 벡터겠지요? 1이 되는 걸 확인하실 수 있고 이건 곧 a^[L]과 같습니다. 여기에서 신경망이 잘 작동하는 것 같지는 않습니다. 고양이일 확률이 20%에 불과하니까요. 이 샘플에 대해서는 잘 작동하지 않네요.
여기에서 신경망을 학습시키기 위한 손실 함수는 무엇일까요? 소프트맥스 분류에서 주로 사용하는 손실 함수는 j=1부터 4까지, 일반적으로는 1부터 C까지겠죠? y_j * log (y^_j)의 합의 음수값입니다. 위 샘플에서 무슨 일이 일어난건지 같이 보면서 얘기해보죠. 여기에서 y_1=y_3=y_4=0이죠? 그리고 y_2만 유일하게 1입니다. 이 합을 구할 때 y_j가 0이면 고려해주지 않아도 됩니다. 따라서 유일하게 남는 항은 -y_2*log(y^_2)겠죠. 여기에다 y_2는 1이니 결국 -log(y^_2)가 되겠네요. 우리 학습 알고리즘이 경사하강법을 이용해서 이 손실 함수의 값을 작게 만들려고 하겠죠? 결국 이 값을 작게 만드는 것이고요. 그러면 결국 y^_2의 값을 가능한 한 크게 만들어야 합니다. 이 값들이 확률이므로 1보다 커질 수는 없죠? 여기서 말이 되는 것이 입력값 x가 고양이의 사진이었으니 그에 대응하는 출력값인 확률을 최대한 키워야겠죠.
즉 일반적으로 손실 함수는 훈련 세트에서 관측에 따른 클래스가 뭐든 간에 그 클래스에 대응하는 확률을 가능한 한 크게 만드는 겁니다. 통계학에서 최대 우도 추정을 본 적이 있다면 최대 우도 추정과 비슷하다는 것을 알 수 있을 겁니다. 무슨 말이지 몰라도 괜찮습니다. 우리가 얘기했던 직관만으로 충분해요. 하나의 훈련 샘플에서 손실 함수를 봤고요.
전체 훈련 세트에 대해 비용 함수 J는 뭘까요? 편향 등의 매개변수를 설정할 때 비용 함수는 여러분이 생각하는 것처럼 전체 훈련 세트에서 학습 알고리즘의 예측에 대한 손실 함수를 합하는 겁니다. 훈련 샘플들에 대해서 말이죠. 그리고 이 비용 함수를 최소로 하기 위해 경사하강법을 쓰셔야하죠.
마지막으로 구현에 관해 살펴보자면 C=4이고 y는 (4,1) 벡터인 상황에서 y^도 (4,1) 벡터죠. Y라는 행렬은 y^[1], y^[2]부터 y^[m]이 되겠죠? 이렇게 수평하게 쌓습니다. 위에 있는 샘플이 첫 번째 훈련 샘플라고 한다면 첫 번째 열은 0 1 0 0이 되겠고요. 두 번째 샘플은 개가 될 수 있겠죠? 세 번째 샘플은 아무 것도 아닐 수 있고요 이렇게 계속합니다. 그러면 Y는 (4,m) 차원의 행렬이 되겠네요. 비슷하게 Y^은 y^(1)부터 y^(m)을 수평하게 쌓은 걸 겁니다. 즉 0.3 0.2 0.1 0.4가y^(1)이 되겠네요. 첫 번째 훈련 샘플에 대한 출력값이니까요. 그러면 Y^도 (4,m) 차원이 될 겁니다.
끝으로 소프트맥스 출력층이 있는 경우 경사하강법을 어떻게 구현할지 봅시다. 이 출력층이 z^[L]을 계산하겠죠? (C,1) 차원이겠죠? 우리 예시에서는 (4,1) 차원이고요. 여기에다 소프트맥스 활성화 함수를 취해서 a^[L] 또는 y^을 얻는 겁니다. 그러면 그 값을 이용해서 손실 함수를 계산할 수 있죠. 이전에 신경망의 정방향 전파를 다룬 적이 있습니다. 손실 함수를 구하는 데 썼죠?
역방향 전파나 경사하강법은 어떤가요? 역방향 전파에서 초기화를 위한 핵심이 되는 식은 마지막 층에서 z^[L]의 미분이 (4,1)벡터인 y^에서 (4,1)벡터인 y를 뺀 것과 같다는 거죠. 클래스가 4개일 때 모두 (4,1) 벡터가 되는 겁니다. 일반적으로 (C,1) 차원이겠죠? 우리의 일반적인 정의를 빌리자면 여기서 dz^[L]은 비용 함수를 z^[L]에 대해 편미분한 겁니다. 미적분학에 능숙하다면 여러분이 직접 유도해볼 수 있습니다. 하지만 처음 시작하는 분이라면 이 공식을 이용해도 됩니다. 이런 식으로 시작을 해서 신경망 전체에 대한 미분을 역방향 전파로 구하는 거죠.
이번 주에 프로그래밍 예제에서는 딥러닝 프레임워크를 다뤄볼텐데요. 주로 정방향 전파에 초점을 맞추면 됩니다. 즉 여러분이 순방향 전파를 하는 법을 정해주면 프레임워크가 스스로 역방향 전파를 어떻게 할지 결정해주니까요. 여러분이 소프트맥스 분류나 회귀를 처음 한다면 이 식을 기억해두시는 것을 추천합니다. 예제에서는 굳이 필요하진 않지만요. 여러분이 사용하실 프로그래밍 프레임워크는 미분 계산을 해 줄테니까요.
이렇게 소프트맥스 분류가 끝났습니다. 이제 두 클래스 중 하나가 아니라 C개의 서로 다른 클래스 중 하나로 분류하는 학습 알고리즘을 구현할 수 있습니다.