
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 이진 탐색
- 인공지능
- 선형대수
- 알고리즘
- AI
- RESNET
- DFS
- rnn
- GRU
- 계수정렬
- 선택정렬
- 큐
- LSTM
- BFS
- 삽입정렬
- 그리디
- 최단 경로
- 딥러닝
- 퀵정렬
- Machine Learning
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 머신러닝
- 다이나믹 프로그래밍
- 재귀함수
- pytorch
- 정렬
- 스택
- Today
- Total
hyeonzzz's Tech Blog
[딥러닝 파이토치 교과서] 5장. 합성곱 신경망 I -(2) 본문
5.3 전이 학습
합성곱 신경망 기반의 딥러닝 모델을 제대로 훈련시키려면 많은 양의 데이터가 필요하다.
이를 해결하기 위한 방법이 전이 학습이다.
전이학습 (transfer learning)
: 이미지넷(ImageNet)처럼 아주 큰 데이터셋을 써서 훈련된 모델의 가중치를 가져와 우리가 해결하려는 과제에 맞게 보정해서 사용하는 것
- 사전 훈련된 모델 : 아주 큰 데이터셋을 사용하여 훈련된 모델
- 비교적 적은 수의 데이터를 가지고도 우리가 원하는 과제를 해결할 수 있다

5.3.1 특성 추출 기법
특성 추출 (feature extractor)
: ImageNet 데이터셋으로 사전 훈련된 모델을 가져온 후 마지막에 완전연결층 부분만 새로 만든다.
즉, 학습할 때는 마지막 완전연결층(이미지의 카테고리를 결정하는 부분)만 학습하고 나머지 계층들은 학습되지 않도록 한다.
- 합성곱층 : 합성곱층과 풀링층으로 구성
- 데이터 분류기(완전연결층) : 추출된 특성을 입력받아 최종적으로 이미지에 대한 클래스를 분류하는 부분
사전 훈련된 네트워크의 합성곱층(가중치 고정)에 새로운 데이터를 통과시키고, 그 출력을 데이터분류기에서 훈련시킨다.
여기서 출력은?
출력 값은 신경망의 마지막 층에서 나오는 활성화 값으로, 각 입력 데이터에 대한 추출된 특징을 나타낸다. 이러한 출력 값은 새로운 데이터의 특징을 표현하고, 이를 기반으로 데이터분류기가 새로운 클래스를 학습할 수 있도록 한다.
사용 가능한 이미지 분류 모델
- Xception
- Inception V3
- ResNet50
- VGG16
- VGG19
- MobileNet

특성 추출 예제
<데이터 전처리>
Resize vs RandomResizedCrop
Resize : 합성곱층을 통과하기 위해 이미지 크기를 조정
RandomResizedCrop : 이미지를 랜덤한 비율로 자른 후 데이터 크기를 조정 -> 데이터 확장


ToTensor : 이미지 데이터를 텐서로 변환
- 이미지 데이터는 픽셀 값의 집합으로 이루어진 형태이다.
- 딥러닝 모델에 입력으로 제공하려면 텐서 형식으로 변환해야 한다.
<행렬의 차원 변경>
np.transpose()
torch.Size가 [32, 3, 224, 224]라는 것은
batch size=32, channel=3, height=224, width=224인 이미지이다. (배치, 채널, 높이 너비)
imshow(np.transpose(samples[i].numpy(), (1,2,0)))
에서의 samples[i]는 i번째 이미지 데이터를 나타내는 PyTorch 텐서이다. 여기서 numpy()를 사용하여 이를 NumPy 배열로 변환하고, np.transpose()를 사용하여 배열의 차원을 변경한다.
numpy로 변환하는 이유
: PyTorch의 텐서(tensor) 형식을 NumPy 배열 형식으로 바꿔서 Matplotlib의 imshow 함수가 인식할 수 있도록 하기 위함
주어진 차원 순서 (1, 2, 0)은 세로, 가로, 채널의 순서로 배열을 재구성하라는 것이다.
따라서 얻어지는 배열은 [224, 224, 3] 크기의 이미지가 된다.
np.arange(24).reshape(2, 3, 4)
np.arange(24)는 0부터 23까지의 연속된 숫자로 이루어진 1차원 배열을 생성한다.
이를 .reshape(2, 3, 4)를 사용하여 2x3x4 형태의 3차원 배열로 변환한다.
여기서 차원의 크기는 각각 다음과 같습니다:
- 첫 번째 차원(가장 바깥쪽 차원): 크기가 2
- 두 번째 차원: 크기가 3
- 세 번째 차원(가장 안쪽 차원): 크기가 4
데이터 예시
[
[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]
]
np.transpose(exam, (2, 1, 0))
(2, 3, 4) -> (4, 3, 2)
데이터 예시
[
[[ 0, 12],
[ 4, 16],
[ 8, 20]],
[[ 1, 13],
[ 5, 17],
[ 9, 21]],
[[ 2, 14],
[ 6, 18],
[10, 22]],
[[ 3, 15],
[ 7, 19],
[11, 23]]
]
<사전 훈련된 모델 내려받기> - 모델 구조를 변경하고 새로운 작업에 맞게 조정
ResNet18
- 50개의 계층으로 구성된 합성곱 신경망
- ImageNet 데이터베이스의 100만 개가 넘는 영상을 이용하여 훈련된 신경망
- 전이 학습에 사용되도록 사전 훈련된 모델을 제공하고 있다
- 단점 - 입력 제약이 매우 크고, 충분한 메모리(RAM)가 없으면 학습 속도가 느릴 수 있다
<완전 연결층 추가>

<모델 객체 생성 및 손실 함수 정의> - 모델을 실제로 학습하기 위해 필요한 준비
<모델 학습을 위한 함수 생성>
_, preds = torch.max(outputs, 1)
주어진 텐서 outputs에서 각 행마다 최댓값과 그 인덱스를 구한다. 반환된 값 중에서 최댓값은 사용하지 않고, 열의 인덱스를 preds에 저장한다. 이렇게 하면 모델의 출력 중에서 각 샘플에 대한 예측 클래스를 알 수 있게 된다.
예를 들어, outputs가 다음과 같은 텐서일 때
outputs = [[0.1, 0.8, 0.3],
[0.6, 0.2, 0.7]]
- 최댓값: [0.8, 0.7]
- 위치의 인덱스(클래스 인덱스): [1, 2]
따라서 preds에는 [1, 2]가 저장된다.
torch.save(model.state_dict(), os.path.join('catanddog/', '{0:0=2d}.pth'.format(epoch)))
현재 모델의 파라미터를 저장한다. 이를 통해 모델의 학습 상태를 저장하고, 나중에 필요할 때 다시 불러와서 사용할 수 있다.
- model.state_dict(): 모델의 파라미터를 담고 있는 딕셔너리를 반환한다. 이 딕셔너리에는 각 층의 파라미터 텐서가 포함되어 있다.
- torch.save(): 주어진 객체를 파일에 저장한다. 첫 번째 인자로는 저장할 객체를 전달하고, 두 번째 인자로는 저장할 파일의 경로를 전달한다.
- os.path.join('catanddog/', '{0:0=2d}.pth'.format(epoch)): 파일 경로를 생성한다. 여기서 catanddog/는 파일을 저장할 디렉토리를 나타내고, {0:0=2d}.pth는 파일 이름을 지정한다. 이 부분에서 {0:0=2d}는 문자열 포매팅을 통해 에포크 번호를 2자리로 지정한다. 예를 들어, 에포크 번호가 1인 경우 01.pth와 같이 파일이 저장된다.
따라서 위 코드는 현재 학습 중인 에포크의 모델 파라미터를 catanddog/ 디렉토리에 에포크 번호를 파일 이름으로 저장한다. 이렇게 저장된 모델은 나중에 필요할 때 torch.load()를 사용하여 불러올 수 있다.
<테스트 데이터 평가 함수 생성>
model.load_state_dict(torch.load(model_path))
특정 경로에 저장된 모델의 상태를 불러와서 현재 모델에 적용하는 역할을 한다. 이를 통해 이전에 학습된 모델의 상태를 가져와서 계속해서 학습을 진행하거나 평가를 수행할 수 있다.
- torch.load(model_path): 주어진 경로(model_path)에서 저장된 모델의 상태를 불러옵니다. 이는 모델의 가중치(weight)와 다른 중요한 파라미터를 포함하는 딕셔너리입니다.
- model.load_state_dict(...): 불러온 상태 딕셔너리를 사용하여 모델의 상태를 업데이트합니다. 이를 통해 모델의 가중치와 다른 파라미터를 이전에 저장된 값으로 설정합니다.
<예측 이미지 출력을 위한 전처리 함수>
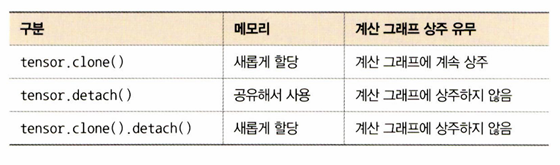
image=tensor.clone().detach().numpy()
- tensor.clone() : 기존 텐서의 내용을 복사한 텐서 생성
- tensor.clone().detach() : 기존 텐서를 복사한 텐서를 생성하지만 기울기에 영향을 주지는 않겠다
tensor.clone() vs tensor.detach() vs tensor.clone().detach()
클리핑
image.clip(0, 1) : image 데이터를 0과 1 사이의 값으로 제한하겠다
add_subplot
한 화면에 여러 개의 이미지를 담기 위해 사용한다

5.3.2 미세 조정 기법
미세 조정 기법
: 특성 추출 기법에서 더 나아가 사전 훈련된 모델과 합성곱층, 데이터 분류기의 가중치를 업데이트하여 훈련시키는 방식
- 특성이 잘못 추출되었다면 미세 조정 기법으로 새로운 이미지 데이터를 사용하여 네트워크의 가중치를 업데이트해서 특성을 다시 추출할 수 있다.
- 즉, 사전 학습된 모델을 목적에 맞게 재학습시키거나 학습된 가중치의 일부를 재학습시키는 것이다.
- 많은 연산량이 필요하기 때문에 GPU를 사용하길 권장한다
훈련 전략
| 데이터셋이 크고 사전 훈련된 모델과 유사성이 작을 경우 | 모델 전체를 재학습 |
| 데이터셋이 크고 사전 훈련된 모델과 유사성이 클 경우 | 합성곱층의 뒷부분(강한 특징이 나타남. 완전연결층과 가까운 부분)과 데이터 분류기(완전연결층)를 학습시킨다 |
| 데이터셋이 작고 사전 훈련된 모델과 유사성이 작을 경우 | 합성곱층의 일부분과 데이터 분류기를 학습시킨다 |
| 데이터셋이 작고 사전 훈련된 모델과 유사성이 클 경우 | 데이터 분류기만 학습시킨다 (데이터가 적기 때문에 많은 계층에 미세 조정 기법을 적용하면 과적합이 발생할 수 있다) |

5.4 설명 가능한 CNN
: 딥러닝 처리 결과를 사람이 이해할 수 있는 방식으로 제시하는 기술
- CNN은 블랙박스와 같아 내부에서 어떻게 동작하는지 설명하기 어렵다
- 이를 해결하려면 CNN 처리 과정을 시각화해야할 필요성이 있다
- 중간 계층부터 최종 분류까지 입력된 이미지에서 특성이 어떻게 추출되고 학습하는지를 시각적으로 설명할 수 있어야 신뢰성을 얻을 수 있다
- CNN의 시각화 방법 - 필터에 대한 시각화, 특성 맵에 대한 시각화
5.4.1 특성 맵 시각화
특정 입력 이미지에 대한 특성 맵을 시각화
: 특성 맵에서 입력 특성을 감지하는 방법을 이해할 수 있도록 돕는 것
특성 맵 시각화 예제
log_softmax()
: 신경망 말단의 결괏값들을 확률 개념으로 해석
softmax는 기울기 소멸 문제에 취약하기 때문에 log softmax를 사용한다

Log-Softmax를 사용하는 것이 기울기 소실 문제를 직접적으로 해결하는 것은 아닙니다. Log-Softmax는 Softmax의 로그 버전으로, 출력의 확률값을 계산할 때 로그를 취하여 계산하는 것입니다.
기울기 소실 문제를 해결하는 데 Log-Softmax가 도움을 줄 수 있는 이유는 다음과 같습니다:
- 수치적 안정성: Softmax 함수는 지수 함수를 사용하므로 큰 입력값에 대해 지수적으로 증가합니다. 이는 수치적으로 불안정한 상황을 만들 수 있습니다. Log-Softmax는 로그를 취하므로 이런 문제를 완화할 수 있습니다.
- Gradient 계산: Log-Softmax를 사용하면 역전파(backpropagation) 과정에서 손실 함수의 그래디언트를 더 쉽게 계산할 수 있습니다. 로그를 취한 후의 확률값은 덧셈으로 계산되므로, Softmax와 달리 곱셈이 아니라 덧셈 연산이 됩니다. 이는 역전파 과정에서 기울기 소실을 줄일 수 있습니다.
하지만 Log-Softmax를 사용하여 기울기 소실 문제를 완전히 해결할 수는 없습니다. 기울기 소실은 주로 네트워크의 깊이나 가중치 초기화 등 여러 요소에 의해 발생하므로, Log-Softmax는 이러한 문제를 완전히 해결하지는 못합니다. 대신 Log-Softmax는 학습을 안정화시키고 수치적 안정성을 높이는데 도움을 줄 수 있습니다.
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
파이토치는 hook 기능을 사용하여 각 계층의 활성화 함수 및 기울기 값을 확인할 수 있다.
register_forward_hook : 순전파 중에 각 네트워크 모듈의 입력 및 출력을 가져오는 것
보간법
이미지 크기를 변경할 경우 변형된 이미지의 픽셀을 추정해서 값을 할당해야 한다.
이미지상에 존재하는 픽셀 데이터들에 대해 근사 함수를 적용해서 새로운 픽셀 값을 구하는 것이 보간법이다.
특성 맵 시각화
0번째 계층 - 입력층과 가까운 계층으로 입력 이미지의 형태가 많이 유지되고 있다
20번째 계층 - 기존 고양이 이미지의 형태는 찾아볼 수 없다
40번째 계층 - 원래 입력 이미지에 대한 형태는 전혀 찾아볼 수 없다. 즉, 출력층에 가까울수록 원래 형태는 찾아볼 수 없고, 이미지 특징들만 전달된다
CNN은 필터와 특성 맵을 시각화해서 CNN 결과의 신뢰성을 확보할 수 있다
5.5 그래프 합성곱 네트워크
: 그래프 데이터를 위한 신경망
5.5.1 그래프란
그래프
: 방향성이 있거나 없는 edge로 연결된 node들의 집합

- node - 원소
- edge - 결합 방법(single, double, triple, aromatic)
5.5.2 그래프 신경망
그래프 신경망 (GNN)
: 그래프 구조에서 사용하는 신경망
그래프 데이터에 대한 표현
1. 인접 행렬 (adjacency matrix)
- 노드 n개를 nxn 행렬로 표현한다
- 이렇게 생성된 인접 행렬 내의 값은 i와 j의 관련성 여부를 만족하는 값으로 채워준다
컴퓨터가 이해하기 쉽게 그래프로 표현하는 과정
2. 특성 행렬 (feature matrix)
- 인접 행렬만으로는 특성을 파악하기 어렵기 때문에 단위 행렬을 적용한다
- 각 입력 데이터에서 이용할 특성을 선택한다
- 특성 행렬에서 각 행은 선택된 특성에 대해 각 노드가 갖는 값을 의미한다

특성 행렬 과정을 거쳐 그래프 특성이 추출된다
5.5.3 그래프 합성곱 네트워크
그래프 합성곱 네트워크(GCN)
:이미지에 대한 합성곱을 그래프 데이터로 확장한 알고리즘
구조

- 그래프 합성곱층 : 그래프 형태의 데이터는 행렬 형태의 데이터로 변환된다
- 리드아웃 : 특성 행렬을 하나의 벡터로 변환하는 함수. 즉, 전체 노드의 특성 벡터에 대해 평균을 구하고 그래프 전체를 표현하는 하나의 벡터를 생성
GCN이 활용되는 곳
- SNS에서 관계 네트워크
- 학술 연구에서 인용 네트워크
- 3D Mesh
'Deep Learning > Pytorch' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(2) (1) | 2024.05.03 |
|---|---|
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(1) (0) | 2024.04.12 |
| [딥러닝 파이토치 교과서] 5장. 합성곱 신경망 I -(1) (1) | 2024.03.29 |
| [딥러닝 파이토치 교과서] 4장. 딥러닝 시작 (0) | 2024.03.20 |
| [딥러닝 파이토치 교과서] 2장. 실습 환경 설정과 파이토치 기초 (0) | 2024.03.14 |



