
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- BFS
- 인공지능
- 삽입정렬
- rnn
- GRU
- 이진 탐색
- Machine Learning
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 알고리즘
- 그리디
- pytorch
- 다이나믹 프로그래밍
- 큐
- 정렬
- 퀵정렬
- RESNET
- 계수정렬
- 머신러닝
- 스택
- DFS
- 선형대수
- 딥러닝
- LSTM
- 선택정렬
- 최단 경로
- AI
- 재귀함수
- Today
- Total
hyeonzzz's Tech Blog
[딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(2) 본문
6.2 객체 인식을 위한 신경망
객체 인식 (object detection) : 이미지나 영상 내에 있는 객체를 식별하는 컴퓨터 비전 기술
- 여러 객체에 대해 각 객체가 무엇인지 분류한다
- 그 객체 위치가 어디인지 박스로 나타내는 위치 검출 문제를 다룬다
따라서, 객체 인식 = 여러 가지 객체에 대한 분류 + 객체의 위치 정보를 파악하는 위치 검출
객체 인식 알고리즘

1단계 객체 인식(1-stage detector)
- 분류와 위치 검출을 동시에 행하는 방법
- 비교적 빠르지만 정확도가 낮다
- YOLO 계열, SSD 계열
2단계 객체 인식(2-stage detector)
- 두 문제를 순차적으로 행하는 방법
- 비교적 느리지만 정확도가 높다
- R-CNN 계열
객체 인식은 자율 주행 자동차, CCTV, 무인 점포 등 많은 곳에서 활용한다
6.2.1 R-CNN
예전의 객체 인식 알고리즘은 슬라이딩 윈도우 방식(sliding window)이었다.
즉, 일정한 크기를 가지는 윈도우를 가지고 이미지의 모든 영역을 탐색하면서 객체를 검출해 내는 방식이다.
알고리즘의 비효율성 때문에 현재는 선택적 탐색 알고리즘을 적용한 후보 영역(region proposal)을 많이 사용한다
R-CNN
: 이미지 분류를 수행하는 CNN + 이미지에서 객체가 있을 만한 영역을 제안해 주는 후보 영역 알고리즘
R-CNN의 수행 과정

- 이미지를 입력으로 받는다
- 2000개의 바운딩 박스를 선택적 탐색 알고리즘으로 추출한 후 잘라 내고(cropping), CNN 모델에 넣기 위해 같은 크기(227*227 픽셀)로 통일한다(warping)
- 크기가 동일한 이미지 2000개에 각각 CNN 모델을 적용한다
- 각각 분류를 진행하여 결과를 도출한다
선택적 탐색
: 객체 인식이나 검출을 위한 가능한 후보 영역을 알아내는 방법
분할 방식을 이용하여 시드(seed)를 선정하고, 그 시드에 대한 완전 탐색을 적용한다
- 초기 영역 생성(sub-segmentation) - 입력된 이미지를 영역 다수 개로 분할한다
- 작은 영역의 통합 - 비슷한 영역으로 통합하는데, greedy 알고리즘을 사용하여 비슷한 영역이 하나로 통합될 때까지 반복한다
- 후보 영역 생성 - 통합된 이미지들을 기반으로 후보 영역(바운딩 박스)을 추출한다
사용되는 용어 의미
- 완전 탐색(exhaustive search) : 후보가 될 만한 대상의 크기 및 비율이 모두 다른 상황을 고려하여 후보 영역을 찾는 기법
- 분할(segmentation) : 영상 데이터의 특성에 따라 분할하여 후보 영역을 선정하는 기법
- 후보 영역(바운딩 박스) : 3D 객체의 형태를 모두 포함할 수 있는 최소 크기의 박스
- 시드(seed) : 영상에서는 특성 기준점의 픽셀에서 점점 의미가 같은 영상 범위까지 픽셀을 확장해 나가면서 분할하는데, 이때 특정 기준점이 되는 픽셀
R-CNN의 단점
- 3단계의 복잡한 학습 과정
- 긴 학습 시간과 대용량 저장 공간
- 객체 검출(object detection) 속도 문제
이러한 문제를 해결하기 위해 Fast R-CNN이 등장했다
6.2.2 공간 피라미드 풀링
기존 CNN 구조들의 문제
- 완전연결층을 위해 입력 이미지를 고정해야 했다. 따라서 신경망을 통과시키려면 이미지를 고정된 크기로 자르거나(crop) 비율을 조정(warp)해야 했다
- 이렇게 하면 물체의 일부분이 잘리거나 본래의 생김새와 달라지는 문제점이 있다
이러한 문제를 해결하기 위해 공간 피라미드 풀링(spatial pyramid pooling)을 도입했다
공간 피라미드 풀링

: 입력 이미지의 크기에 관계없이 합성곱층을 통과시키고, 완전연결층에 전달되기 전에 특성 맵들을 동일한 크기로 조절해 주는 풀링층을 적용하는 기법
- 입력 이미지의 크기를 조절하지 않고 합성곱층을 통과시키기 때문에 원본 이미지의 특징이 훼손되지 않는 특성 맵을 얻을 수 있다
- 이미지 분류나 객체 인식 같은 여러 작업에 적용할 수 있다
6.2.3 Fast R-CNN
R-CNN은 바운딩 박스마다 CNN을 돌리고, 분류를 위한 긴 학습 시간이 문제였다
R-CNN의 속도 문제를 개선하려고 Rol 풀링을 도입한 Fast R-CNN이 나왔다
Fast R-CNN

: 선택적 탐색에서 찾은 바운딩 박스 정보가 CNN을 통과하면서 유지되도록 하고
최종 CNN 특성 맵은 풀링을 적용하여 완전연결층을 통과하도록 크기를 조정한다
- 바운딩 박스마다 CNN을 돌리는 시간을 단축할 수 있다
Rol 풀링
: 크기가 다른 특성 맵의 영역마다 스트라이드를 다르게 최대 풀링을 적용하여 결괏값 크기를 동일하게 맞추는 방법


박스 한 개가 픽셀 한 개를 뜻하는 특성 맵이 있다고 하자
8*8 특성맵(①)에서 선택적 탐색으로 뽑아냈던 7*5 후보 영역(②)이 있으며,
이것을 2*2로 만들기 위해 스트라이드(7/2=3, 5/2=2)로 풀링 영역(③)을 정하고
최대 풀링을 적용하면 2*2 결과(④)를 얻을 수 있다
6.2.4 Faster R-CNN
'더욱 빠른' 객체 인식을 수행하기 위한 네트워크이다
기존 Fast R-CNN 속도의 걸림돌이었던 후보 영역 생성을 CNN 내부 네트워크에서 진행할 수 있도록 설계했다
기존 Fast R-CNN에 후보 영역 추출 네트워크(Region Proposal Network, RPN)를 추가한 것이 핵심이다
외부의 느린 선택적 탐색(CPU로 계산) 대신 내부의 빠른 RPN(GPU로 계산)을 사용한다

RPN은 마지막 합성곱층 다음에 위치한다
그 뒤에 Fast R-CNN과 마찬가지로 Rol 풀링과 분류기, 바운딩 박스 회귀가 위치한다
후보 영역 추출 네트워크(Region Proposal Network, RPN)
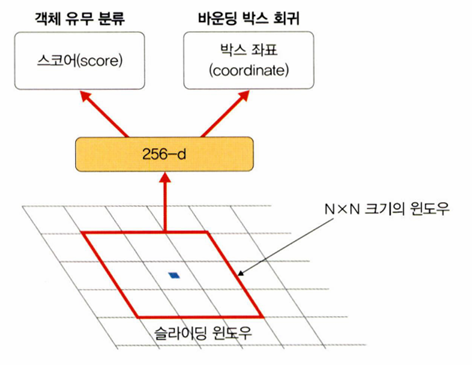
- 특성 맵 N*N 크기의 작은 윈도우 영역을 입력으로 받고, 해당 영역에 객체의 존재 유무 판단을 위해 이진 분류를 수행하는 작은 네트워크를 생성한다
- 바운딩 박스 회귀 또한 위치 보정(좌표점 추론)을 위해 추가한다
- 모든 영역에 대한 객체의 존재 유무를 확인하기 위해 슬라이딩 윈도우 방식으로 앞서 설계한 작은 윈도우 영역(N*N 크기)을 이용하여 객체를 탐색한다
하지만 후보 영역 추출 네트워크는 이미지에 존재하는 객체들의 크기와 비율이 다양하기 때문에 고정된 N*N 크기의 입력만으로 다양한 크기와 비율의 이미지를 수용하기 어려운 단점이 있다
이런 단점을 보완하기 위해
앵커(anchor)

: 여러 크기와 비율의 레퍼런스 박스(reference box) k개를 미리 정의하고
각각의 슬라이딩 윈도우 위치마다 박스 k개를 출력하도록 설계한다
즉, 후보 영역 추출 네트워크의 출력 값은
모든 앵커 위치에 대해 각각 객체와 배경을 판단하는 2k개의 분류에 대한 출력과
x, y, w, h 위치 보정 값을 위한 4k개의 회귀 출력을 갖는다
예를 들어 특성 맵 크기가 w*h라면 하나의 특성 맵에 앵커가 총 w*h*k개 존재한다
6.3 이미지 분할을 위한 신경망
이미지 분할(image segmentation)
: 신경망을 훈련시켜 이미지를 픽셀 단위로 분할하는 것
이미지를 픽셀 단위로 분할하여 이미지에 포함된 객체를 추출한다
대표적인 네트워크 : 완전 합성곱 네트워크, 합성곱 & 역합성곱 네트워크, U-Net, PSPNet, DeepLabv3/DeepLabv3+
6.3.1 완전 합성곱 네트워크
완전연결층의 한계
- 고정된 크기의 입력만 받아들인다
- 완전연결층을 거친 후에는 위치 정보가 사라진다
이러한 문제를 해결하기 위해 완전연결층을 1x1 합성곱으로 대체하는 것이 완전 합성곱 네트워크이다
완전 합성곱 네트워크(Fully Convolutional Network, FCN)
: 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을 변형시켜 이미지 분할에 적합하도록 만든 네트워크

다음과 같이 AlexNet 아래쪽에서 사용되었던 완전연결층 3개를 1x1 합성곱으로 변환하면
위치 정보가 남아 있기 때문에 히트맵(heatmap) 그림과 같이 고양이의 위치를 확인할 수 있다
또한 합성곱층으로 사용되기 때문에 입력 이미지에 대한 크기 제약이 사라진다
6.3.2 합성곱 & 역합성곱 네트워크
완전 합성곱 네트워크의 한계
- 여러 단계의 합성곱층과 풀링층을 거치면서 해상도가 낮아진다
- 낮아진 해상도를 복원하기 위해 업 샘플링 방식을 사용하기 때문에 이미지의 세부 정보들을 잃어버리는 문제가 발생한다
이러한 문제를 해결하기 위해 역합성곱 네트워크를 도입한 것이 합성곱 & 역합성곱 네트워크이다
역합성곱
: CNN의 최종 출력 결과를 원래의 입력 이미지와 같은 크기로 만들고 싶을 때 사용한다
- 시멘틱 분할(semantic segmentation)에 활용할 수 있다 - (이미지 내에 있는 물체들을 의미 있는 단위로 분할하는 것)
- 업 샘플링(upsampling)이라고도 한다
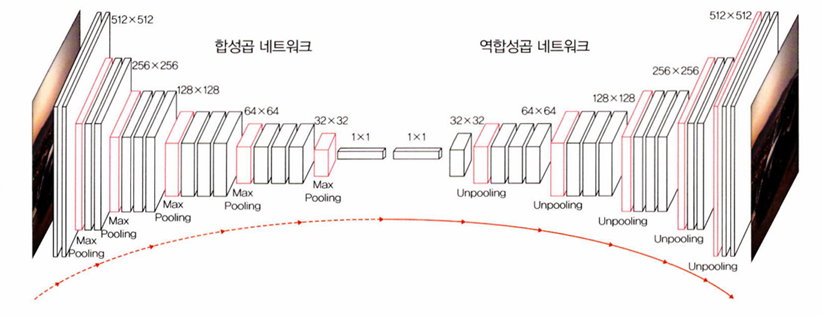
역합성곱 동작 방식
CNN에서 합성곱층은 합성곱을 사용하여 특성 맵 크기를 줄인다
역합성곱은 반대로 특성 맵 크기를 증가시키는 방식으로 동작한다

- 각각의 픽셀 주위에 제로 패딩(zero-padding)을 추가한다
- 패딩된 것에 합성곱 연산을 수행한다
파란색 픽셀이 입력이며, 초록색 픽셀이 출력이다.
파란색 픽셀 주위로 흰색 제로 패딩을 수행하고, 회색 필터로 합성곱 연산을 수행하면 초록색이 출력된다.
6.3.3 U-Net
U-Net
: 바이오 메디컬 이미지 분할을 위한 합성곱 신경망
U-Net 특징
1. 속도가 빠르다
: 기존 슬라이딩 윈도우 방식은 이전 패치(patch)에서 검증이 끝난 부분을 다음 패치에서 또 검증하기 때문에 속도가 느렸다. 하지만 U-Net은 이미 검증이 끝난 패치는 건너뛰기 때문에 속도가 빠르다

2. 트레이드오프(trade-off)에 빠지지 않는다
: 일반적으로 패치 크기가 커진다면 넓은 범위의 이미지를 인식하는 데 뛰어나기 때문에 컨텍스트(context) 인식에 탁월하다. 하지만 지역화에는 한계가 있다. U-Net은 컨텍스트 인식과 지역화 트레이드오프 문제를 개선했다
※ 지역화
: 이미지 안에 객체 위치 정보를 출력해 주는 것
- 주로 바운딩 박스를 사용
- 바운딩 박스의 네 꼭지점 픽셀 좌표가 출력되는 것이 아닌 왼쪽 위(left top), 오른쪽 아래(right bottom) 좌표를 출력한다

U-Net 구조
: FCN을 기반으로 구축되었으며, 수축 경로(contracting path)와 확장 경로(expansive path)로 구성되어 있다
수축 경로 - 컨텍스트를 포착
확장 경로 - 특성 맵을 업 샘플링하고 수축 경로에서 포착한 특성 맵의 컨텍스트와 결합하여 정확한 지역화를 수행함

- 3x3 합성곱이 주를 이룬다
- 각 합성곱 블록은 3x3 합성곱 2개로 구성되어 있으며, 그 사이에 드롭아웃(dropout)이 있다.
왼쪽 수축 경로
- 3x3 합성곱 두개로 구성된 것이 4개가 있는 형태이다
- 각 블록은 최대 풀링(maxpool)을 이용하여 크기를 줄이면서 다음 블록으로 넘어간다
오른쪽 확장 경로
- 합성곱 블록에 up-conv라는 것을 앞에 붙였다
- 수축 과정에서 줄어든 크기를 다시 키워 가면서 합성곱 블록을 이용하는 형태이다
즉, 크기가 다양한 이미지의 객체를 분할하기 위해 크기가 다양한 특성 맵을 병합할 수 있도록 다운 샘플링과 업 샘플링을 순서대로 반복하는 구조이다
6.3.4 PSPNet
PSPNet(Pyramid Scene Parsing Network)
시멘틱 분할 알고리즘
완전연결층의 한계를 극복하기 위해 피라미드 풀링 모듈을 추가했다
PSPNet 훈련 과정

- 이미지 출력이 서로 다른 크기가 되도록 여러 차례 풀링을 한다. 즉, 1x1, 2x2, 3x3, 6x6 크기로 풀링을 수행하는데, 이때 1x1 크기의 특성 맵은 가장 광범위한 정보를 담는다. 각각 다른 크기의 특성 맵은 서로 다른 영역들의 정보를 담는다고 이해하면 된다.
- 이후 1x1 합성곱을 사용하여 채널 수를 조정한다. 풀링층 개수를 N이라고 할 때 출력 채널 수=입력 채널 수/N이 된다.
- 이후 모듈의 입력 크기에 맞게 특성 맵을 업 샘플링한다. 이 과정에서 양선형 보간법(bilinear interpolation)이 사용된다.
- 원래의 특성 맵과 1~3 과정에서 생성한 새로운 특성 맵들을 병합한다.
양선형 보간법
※ 보간법(interpolation)
: 화소 값을 할당받지 못한 영상(영상의 빈 공간)의 품질은 안 좋을 수밖에 없는데, 이때 빈 화소에 값을 할당하여 좋은 품질의 영상을 만드는 방법을 의미한다.
보간법에는 선형 보간법(linear interpolation)과 양선형 보간법(bilinear interpolation)이 있다
선형 보간법
: 원시 영상의 화소 값 두 개를 사용하여 원하는 좌표에서 새로운 화소 값을 계산하는 방법
양선형 보간법
: 화소당 선형 보간을 3번 수행하며, 새롭게 생성된 화소는 가장 가까운 화소 4개에 가중치를 곱한 값을 합해서 얻는다

위의 그림으로 양선형 보간법을 설명하겠다
직사각형의 4개 꼭지점에 값이 주어져 있을 때, 이 사각형 내부에 있는 임의의 점(P)에 대한 값을 추정해 보자
점 P에서 x축 방향으로 거리를 w1, w2라고 하며, y축 방향으로 거리를 h1, h2라고 하자. 이때 알려진 네 점에서 데이터 값을 A, B, C, D라고 할 때, 양선형 보간법에 따라 점 P의 값은 다음과 같이 계산된다.

6.3.5 DeepLabv3/DeepLabv3+
DeepLabv3/DeepLabv3+
완전연결층의 단점을 보완하기 위해 Atrous 합성곱을 사용하는 네트워크
- 인코더와 디코더 구조를 가진다
- 인코더-디코더 구조에서는 불가능했던 인코더에서 추출된 특성 맵의 해상도를 Atrous 합성곱을 도입하여 제어할 수 있도록 했다
DeepLab의 인코더-디코더 구조

Atrous 합성곱
- Atrous 합성곱은 다음 그림과 같이 필터 내부에 빈 공간을 둔 채로 작동한다
- 얼마나 많은 빈 공간을 가질지 결정하는 파라미터로 rate가 있다
- rate=1일 경우 기존 합성곱과 동일하게 빈 공간을 가지며, r이 커질수록 빈 공간은 더 많아진다

보통 이미지 분할에서 높은 성능을 내려면 수용 영역(receptive field)의 크기가 중요하다.
수용 영역을 확대하여 특성을 찾는 범위를 넓게 해주기 때문이다. Atrous 합성곱을 활용하면 파라미터 수를 늘리지 않으면서도 수용 영역을 크게 키울 수 있기 때문에 이미지 분할 분야에서 많이 사용한다.
즉, 다음 그림과 같이 일반적인 CNN을 적용하면 출력은 입력에 비해 1/32로 줄어들지만,
Atrous 합성곱을 적용하면 1/8로 줄어든다. 따라서 특성 맵 크기가 기존 대비 4배 보존된 것을 확인할 수 있다

수용 영역
: 외부 자극이 전체에 영향을 주는 것이 아니라 특정 영역에만 영향을 준다는 의미이다.
영상에서 특정 위치에 있는 픽셀들은 그 주변에 있는 일부 픽셀과 연관성은 높지만, 거리가 멀어질수록 그 영향은 감소하게 된다. 영상 전체 영역에 대해 서로 동일한 중요도를 부여하여 처리하는 대신, 특정 범위를 한정해서 처리하여 효과적으로 훈련을 수행하는 것이 수용 영역이다.
'Deep Learning > Pytorch' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 7장. 시계열 분석 -(2) (0) | 2024.05.14 |
|---|---|
| [딥러닝 파이토치 교과서] 7장. 시계열 분석 -(1) (0) | 2024.05.10 |
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(1) (0) | 2024.04.12 |
| [딥러닝 파이토치 교과서] 5장. 합성곱 신경망 I -(2) (2) | 2024.04.03 |
| [딥러닝 파이토치 교과서] 5장. 합성곱 신경망 I -(1) (1) | 2024.03.29 |



