※ OneHotEncoder의 경우 입력 값으로 2차원 데이터를 요구한다. (DataFrame은 2차원 데이터 구조)
※OneHotEncoder는 여러 제약으로 인해 많이 사용되지 않는다.
※그 대신, pandas의 get_dummies()를 더 많이 활용
10.1.2 횟수 기반 임베딩
횟수 기반
: 단어가 출현한 빈도를 고려하여 임베딩
카운터 벡터와 TF-IDF가 있다.
카운터 벡터(counter vector)
: 문서 집합에서 단어를 토큰으로 생성하고 각 단어의 출현 빈도수를 이용하여 인코딩해서 벡터를 만드는 방법
즉, 토크나이징과 벡터화가 동시에 가능한 방법
CountVectorizer()
문서를 토큰 리스트로 변환
토큰의 출현 빈도를 센다
문서를 인코딩하고 벡터로 변환한다
from sklearn.feature_extraction.text import CountVectorizer
# 텍스트 데이터
texts = ["I love machine learning", "I love learning"]
# 카운트 벡터화 객체 생성
vectorizer = CountVectorizer()
# 텍스트 데이터를 카운트 벡터화
X = vectorizer.fit_transform(texts)
# 벡터화된 결과를 배열 형태로 변환
X_array = X.toarray()
# 결과 출력
print("어휘 사전:", vectorizer.get_feature_names_out())
print("벡터화된 데이터:\n", X_array)
1. 빈도수의 0값 방지 2. 적절한 스케일링 : 예를 들어, 원래 빈도수가 1과 10인 단어가 있다면, 로그 스케일에서는 각각 log(1+1)와 log(10+1)로 변환되어 0과 1이라는 큰 차이에서 0.69와 2.39라는 상대적으로 작은 차이로 줄어든다. 3. 중요도 조정 문서 내에서 많이 등장하는 단어의 영향력을 줄여준다.
DF(Document Frequency)(문서 빈도) : 한 단어가 전체 문서에서 얼마나 공통적으로 많이 등장하는지
즉, 특정 단어가 나타난 문서 개수
특정 단어 t가 모든 문서에 등장하는 일반적인 단어(a, the)라면 TF-IDF 가중치를 낮추어 줄 필요가 있다. 따라서 DF 값이 클수록 TF-IDF 가중치 값을 낮추기 위해 DF값에 역수를 취하는데 이 값이 IDF이다. 역수를 취하면 전체 문서 개수가 많아질수록 IDF값도 커지므로 IDF는 log를 취해야 한다.
특정 단어가 발생하는 빈도가 0이라면 분모가 0이 되는 상황이 발생한다. 이를 방지하고자 분모에 1을 더해 주는 것을 스무딩(smoothing)이라고 한다.
TF-IDF가 사용되는 상황
키워드 검색을 기반으로 하는 검색 엔진
중요 키워드 분석
검색 엔진에서 검색 결과의 순위를 결정
from sklearn.feature_extraction.text import TfidfVectorizer
# 분석할 문서들을 리스트로 정의
doc = ['I like machine learning', 'I love deep learning', 'I run everyday']
# TF-IDF 벡터화를 위한 TfidfVectorizer 객체 생성
# min_df=1은 최소 문서 빈도를 1로 설정하여 모든 단어를 포함함
tfidf_vectorizer = TfidfVectorizer(min_df=1)
# 문서를 TF-IDF 벡터로 변환
tfidf_matrix = tfidf_vectorizer.fit_transform(doc)
# TF-IDF 행렬을 전치하여 문서 간 유사도 계산
doc_distance = (tfidf_matrix * tfidf_matrix.T)
# 유사도를 위한 행렬의 크기 출력
print ('유사도를 위한', str(doc_distance.get_shape()[0]), 'x', str(doc_distance.get_shape()[1]), 'matrix를 만들었습니다.')
# 문서 간 유사도 행렬 출력
print(doc_distance.toarray())
유사도를 위한 3 x 3 matrix를 만들었습니다.
[[1. 0.224325 0. ]
[0.224325 1. 0. ]
[0. 0. 1. ]]
TF-IDF 값은 특정 문서 내에서 단어의 출현 빈도가 높거나 전체 문서에서 특정 단어가 포함된 문서가 적을수록 TF-IDF 값이 높다. 따라서 이 값을 사용하여 문서에 나타나는 흔한 단어(a, the)들을 걸러 내거나 특정 단어에 대한 중요도를 찾을 수 있다.
10.1.3 예측 기반 임베딩
예측 기반 임베딩
: 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식
대표적으로 Word2Vec이 있다.
Word2Vec(워드투벡터)
: 신경망 알고리즘. 주어진 텍스트에서 텍스트의 각 단어마다 하나씩 일련의 벡터를 출력한다.
단어의 의미적 유사성을 반영한 고정된 크기의 벡터를 생성한다.
출력 벡터가 2차원 그래프에 표시될 때, 의미론적으로 유사한 단어의 벡터는 서로 가깝게 표현된다.
서로 가깝다는 의미는 코사인 유사도를 이용하여 단어 간의 거리를 측정한 결과로 나타나는 관계성을 의미한다.
즉, 특정 단어의 동의어를 찾을 수 있다.
수행 과정
일정한 크기의 윈도우로 분할된 텍스트를 입력으로 사용한다.
분할된 텍스트는 한 쌍의 대상 단어와 컨텍스트로 네트워크에 공급된다.
예를 들어 대상 단어는 'one'이고 컨텍스트는 and, I, love, this 단어로 구성된다.
네트워크의 은닉층에는 각 단어에 대한 가중치가 포함되어 있다.
이제 CBOW와 skip-gram을 이용하여 단어 간 유사성을 살펴보겠다
CBOW(Continuous Bag Of Words) - (주변 단어 -> 관련 단어 추정)
보통 입력 단어 주변의 단어 k개를 문맥으로 보고 예측 모형을 만든다. (k = 윈도우 크기)
model2 = gensim.models.Word2Vec(data, min_count = 1, vector_size = 100,
window = 5, sg = 1) # skip-gram 모델 사용
print("Cosine similarity between 'peter' " +
"wendy' - Skip Gram : ",
model2.wv.similarity('peter', 'wendy')) # 결과 출력
데이터 성격, 분석에 대한 접근 방법 및 도출하고자 하는 결론 등을 종합적으로 고려하여 CBOW와 skip-gram 중 필요한 라이브러리를 사용할 수 있어야 한다.
FastText(패스트텍스트)
: 워드투벡터의 단점을 보완하고자 페이스북에서 개발한 임베딩 알고리즘
예를 들어 apple이라는 단어를 app, ppl, ple와 같은 여러 n-grams로 분해해 학습하므로 서브워크 정보도 학습한다.
기존 Word2Vec
분산 표현을 이용하여 단어의 분산 분포가 유사한 단어들에 비슷한 벡터 값을 할당하여 표현한다.
사전에 없는 단어에 대해서는 벡터 값을 얻을 수 없다.
자주 사용되지 않는 단어에 대해서는 학습이 불안정하다.
FastText
단어 표현(word representation) 방법을 사용한다.
노이즈에 강하며, 새로운 단어에 대해서는 형태적 유사성을 고려한 벡터값을 얻기 때문에 자연어 처리 분야에서 많이 사용된다.
from gensim.test.utils import common_texts
from gensim.models import FastText
model = FastText('./peter.txt', vector_size=4, window=3, min_count=1, epochs=10)
패스트텍스트가 워드투벡터 단점을 극복하는 방법
1. 사전에 없는 단어에 벡터 값을 부여하는 방법
패스트텍스트는 단어를 n-gram으로 표현한다. n의 설정에 따라 단어의 분리 수준이 결정된다. n을 3으로 설정하면 This is Deep Learning Book은 다음과 같이 분리된다.
n 값에 따른 부분 단어는 다음과 같다.
n=1 : unigram
n=2 : bigram
n=3 : trigram
사전에 없는 단어가 등장한다면 n-gram으로 분리된 부분 단어와 유사도를 계산하여 의미를 유추할 수 있다.
2. 자주 사용되지 않는 단어에 학습 안정성을 확보하는 방법
기존 Word2Vec
단어의 출현 빈도가 적으면 임베딩의 정확도가 낮다.
참고할 수 있는 경우의 수가 적기 때문에 상대적으로 정확도가 낮아 임베딩되지 않는다.
FastText
등장 빈도수가 적더라도, n-gram으로 임베딩하기 때문에 참고할 수 있는 경우의 수가 많다.
자주 사용되지 않는 단어에서도 정확도가 높다.
10.1.4 횟수/예측 기반 임베딩
GloVe(글로브)
: 횟수 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec 단점을 보완하기 위한 모델
LSA(Latent Semantic Analysis) : 텍스트 데이터에서 숨겨진 의미적 구조를 발견하기 위한 통계적 기법
LSA는 단어와 문서 간의 관계를 분석하여 고차원의 희소 행렬을 낮은 차원의 의미 공간으로 변환한다. 이를 통해 단어 간의 유사성을 파악하고 문서의 주제를 식별할 수 있다.
단어에 대한 글로벌 동시 발생 활률(global co-occurrence statistics) 정보를 포함하는 단어 임베딩 방법
단어에 대한 통계 정보와 skip-gram을 합친 방식
skip-gram을 사용하되 통계적 기법이 추가된 것
단어 간 관련성을 통계적 방법으로 표현해 준다
Word2Vec와 GloVe 비교
Word2Vec
훈련 방식: Word2Vec는 예측 기반 모델로, CBOW(Continuous Bag of Words)와 Skip-gram 두 가지 알고리즘을 사용하여 단어의 문맥을 예측하면서 벡터를 학습한다.
지역적 정보: Word2Vec는 문맥 창 내의 단어들에 집중하여 로컬 정보를 캡처한다.
단어 간의 관계: 단어의 의미적 유사성과 관계를 벡터 공간에서 잘 나타낸다.
GloVe
훈련 방식: GloVe는 카운트 기반 모델로, 전체 코퍼스의 전역적인 동시 출현 확률을 사용하여 단어 벡터를 학습한다.
전역적 정보: GloVe는 전체 코퍼스의 전역적인 단어 동시 출현 행렬을 사용하여 글로벌한 정보를 캡처한다.
단어 간의 관계: 전역적 통계를 반영하여 단어 벡터를 생성하므로, 특정 단어 쌍 간의 관계를 명확하게 학습할 수 있다.
GloVe를 Word2Vec 포맷으로 변환하는 이유
GloVe를 이용하는데 Word2Vec 포맷으로 변환하는 주된 이유는 다음과 같습니다:
라이브러리 지원:
gensim과 같은 라이브러리는 Word2Vec 포맷을 기본적으로 지원합니다. 따라서 GloVe 벡터를 gensim에서 사용하려면 Word2Vec 포맷으로 변환해야 합니다.
많은 자연어 처리 라이브러리와 도구들이 Word2Vec 포맷을 표준으로 사용합니다.
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
from gensim.test.utils import datapath, get_tmpfile
# GloVe 파일의 경로를 설정합니다.
glove_file = datapath('glove.6B.100d.txt')
# 변환된 Word2Vec 포맷 파일을 저장할 임시 파일 경로를 설정합니다.
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
# GloVe 파일을 Word2Vec 포맷으로 변환합니다.
glove2word2vec(glove_file, word2vec_glove_file)
# 변환된 Word2Vec 포맷의 파일을 로드합니다.
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
# 'king' 단어의 벡터를 출력합니다.
print(model['king'])
# 'king'과 유사한 단어들을 출력합니다.
print(model.most_similar('king'))
10.2 트랜스포머 어텐션
어텐션(attention)
언어 번역에서 사용되기 때문에 인코더와 디코더 네트워크를 사용한다.
인코더(Encoder): 입력 시퀀스를 받아들여 일련의 은닉 상태(hidden states)를 생성합니다. 이 은닉 상태들은 입력 시퀀스의 각 단어에 대한 정보가 담겨 있습니다.
디코더(Decoder): 인코더의 은닉 상태와 이전의 디코더 은닉 상태를 사용하여 출력 시퀀스를 생성합니다.
인코더
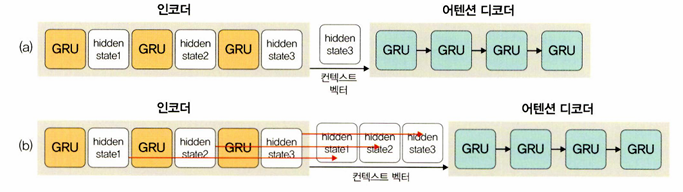
입력에 대한 벡터 변환을 인코더에서 처리하고 모든 벡터를 디코더로 보낸다.
모든 벡터를 전달하는 이유 : 시간이 흐를수록 초기 정보를 잃어버리는 기울기 소멸 문제를 해결하기 위해서
단점 : 모든 벡터가 전달되기 때문에 행렬 크기가 굉장히 커진다.
해결 : 소프트맥스 함수를 사용하여 가중합을 구하고 그 값을 디코더에 전달한다.
디코더
가중합만 전달되었더라도 부담이다.
은닉 상태에 대해 중점적으로 집중해서 보아야 할 벡터를 소프트맥스 함수로 점수를 매긴 후 각각을 은닉 상태의 벡터들과 곱한다.
이 은닉 상태를 모두 더해서 하나의 값으로 만든다.
즉, 모든 벡터 중에서 꼭 살펴보아야 할 벡터들에 집중하겠다는 의미이다.
트랜스포머(transformer)
: 어텐션을 극대화하는 방법
"Attention is All You Need" 논문에서 발표된 것
인코더와 디코더를 여러 개 중첩시킨 구조
이때, 각각의 인코더와 디코더를 블록(block)이라고 한다.
논문에서는 인코더 블록과 디코더 블록을 6개씩 중첩시킨 구조를 사용한다.
인코더 블록 구조
단어를 벡터로 임베딩하고, 이를 셀프 어텐션과 전방향 신경망으로 전달한다.
셀프 어텐션은 문장 안에서 단어 간 관계를 파악한다.
셀프 어텐션에서 파악된 단어 간 관계는 전방향 신경망으로 전달된다.
디코더 블록 구조
셀프 어텐션 + 인코더-디코더 어텐션 + 전방향 신경망
셀프 어텐션 층 : 인코더와 동일하다 (문장에서 단어 간 관계 파악)
인코더-디코더 어텐션 : 인코더가 처리한 정보를 받아 어텐션 메커니즘을 수행하고, 전방향 신경망으로 데이터를 전달한다.
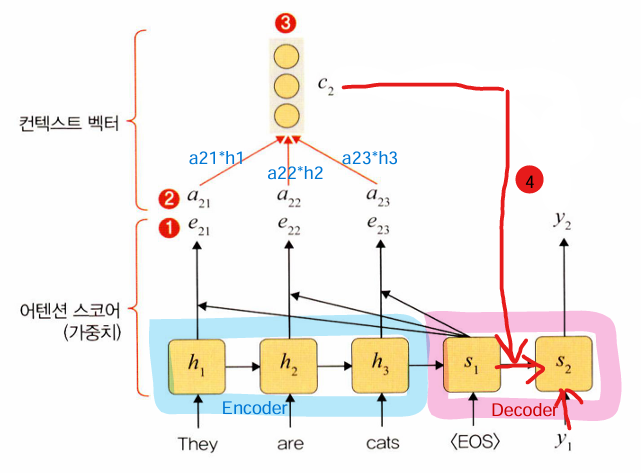
<어텐션 매커니즘>
1. 어텐션 스코어 구하기
: 현재 디코더의 시점 i에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 값(h_j)이 디코더의 이전 시점의 은닉 상태(s_i-1)와 얼마나 관련이 있는지를 판단하는 값
인코더의 모든 은닉 상태의 값(h_j)과 디코더에서의 이전 시점의 은닉 상태(s_i-1)값을 이용하여 구할 수 있다.
2. softmax 함수에 적용하여 확률로 변환하기
이렇게 계산된 0~1 사이의 값들이 특정 시점에 대한 가중치, 즉 시간의 가중치가 된다.
3. 컨텍스트 벡터 구하기
: 시간의 가중치(a_ij)와 은닉 상태(h_j)의 가중합을 계산하면 하나의 벡터가 계산된다.
4. 디코더의 은닉 상태(s_t) 구하기
컨텍스트 벡터(c_t)와 디코더 이전 시점의 은닉 상태(s_t-1)와 출력(y_t-1)이 필요하다.
어텐션이 적용된 인코더-디코더의 수식에서는 컨텍스트 벡터(c_i)가 계속 변하고 있다.
어텐션이 적용되지 않은 인코더-디코더 수식에서는 컨텍스트 벡터(c)가 고정되어 있다.
순전파 과정을 통해 정리
어텐션 스코어 계산 : 'They are cats'라는 입력 시퀀스에 대해 먼저 s1(디코더의 이전 시점 은닉 상태)과 모든 인코더 은닉 상태에 대한 어텐션 스코어(e21, e22, e23)를 계산한다.
소프트맥스 함수 적용 : 어텐션 스코어(e21, e22, e23)를 구했으면 소프트맥스 함수를 적용하여 시간의 가중치(a21, a22, a23)를 구한다.
컨텍스트 벡터(c2) 계산 : '시간의 가중치'와 인코더의 은닉 상태 값들을 이용하여 가중합을 계산함으로써 컨텍스트 벡터(c2)를 구한다.
다음 디코더의 은닉 상태(s2) 출력 : 앞에서 구한 컨텍스트 벡터와 디코더 이전 시점의 은닉 상태와 출력을 이용하여 최종적으로 다음 디코더의 은닉 상태(s2)를 출력한다.
디코더의 은닉 상태의 역할 : 다음에 어떤 단어를 출력할지를 결정하는 데 필요한 모든 문맥 정보를 담고 있다.
1. 문맥 정보 저장 - 디코더의 은닉 상태는 이전에 생성된 모든 단어와 입력 시퀀스에 대한 정보를 요약한다. 이는 다음 단어를 예측할 때 필요한 문맥을 제공한다. 2. 출력 단어 예측 - 디코더의 은닉 상태는 다음 단어를 예측하는 데 사용된다. 이는 디코더의 현재 은닉 상태와 어텐션 메커니즘에서 계산된 컨텍스트 벡터를 사용하여 출력 단어를 결정한다. 3. 상호작용 - 디코더는 인코더의 은닉 상태와 어텐션 메커니즘을 통해 상호작용하여, 입력 시퀀스의 중요한 정보를 반영한다. 이는 디코더가 다음에 출력할 단어를 예측하는 데 도움을 준다.
10.2.1 seq2seq
seq2seq
: 입력 시퀀스에 대한 출력 시퀀스를 만들기 위한 모델
시퀀스 레이블링 vs 시퀀스투시퀀스
시퀀스 레이블링 (sequence labeling) : 입력 단어가 x1, x2, ..., xn이라면 출력은 y1, y2, ..., yn이 되는 형태 입력과 출력에 대한 문자열이 같다. 품사 판별이 주 목적
시퀀스투시퀀스 (seq2seq) : 입력 시퀀스와 의미가 동일한 출력 시퀀스를 만드는 것 x, y 간의 관계는 중요하지 않다. 각 시퀀스의 길이도 서로 다를 수 있다. 번역에 초점을 둔 모델
<seq2seq를 파이토치로 구현 (영어 -> 프랑스어)>
1. 라이브러리 호출
2. 데이터 준비
re 모듈
: 정규표현식을 사용하고자 할 때 사용
(정규표현식 : 특정한 규칙을 갖는 문자열의 집합을 표현하기 위한 형식)
import re
com = re.compile('[cats]')
com.findall('I love cats.')