
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- BFS
- 퀵정렬
- rnn
- LSTM
- 그리디
- 머신러닝
- 딥러닝
- 인공지능
- 다이나믹 프로그래밍
- 정렬
- pytorch
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 선형대수
- 이진 탐색
- 스택
- 선택정렬
- GRU
- RESNET
- AI
- Machine Learning
- DFS
- 최단 경로
- 알고리즘
- 계수정렬
- 삽입정렬
- 재귀함수
- 큐
- Today
- Total
hyeonzzz's Tech Blog
[딥러닝 파이토치 교과서] 8장. 성능 최적화 본문
8.1 성능 최적화
8.1.1 데이터를 사용한 성능 최적화
데이터를 사용한 성능 최적화 방법
: 많은 데이터를 수집하는 것
- 최대한 많은 데이터 수집하기 : 딥러닝이나 머신 러닝 알고리즘은 데이터양이 많을수록 성능이 좋다. 따라서 가능한 많은 데이터를 수집해야 한다.(빅데이터)
- 데이터 생성하기 : 많은 데이터를 수집할 수 없다면 데이터를 만들어 사용할 수 있다.
- 데이터 범위 조정하기 : 활성화 함수로 sigmoid를 사용한다면 데이터셋 범위를 0~1의 값을 갖도록 하고, tanh를 사용한다면 데이터셋 범위를 -1~1의 값을 갖도록 조정할 수 있다
정규화, 규제화, 표준화도 성능 향상에 도움이 된다
8.1.2 알고리즘을 이용한 성능 최적화
알고리즘을 이용한 성능 최적화 방법
- 머신러닝과 딥러닝을 위한 알고리즘은 상당히 많다
- 유사한 용도의 알고리즘들을 선택하여 모델을 훈련시켜 보고 최적의 알고리즘을 선택해야 한다
- 머신러닝 - SVM, K-최근접 이웃 알고리즘 등
- 시계열 데이터 - RNN, LSTM, GRU 등
8.1.3 알고리즘 튜닝을 위한 성능 최적화
알고리즘 튜닝을 위한 성능 최적화
: 다양한 하이퍼파라미터를 변경하면서 훈련시키고 최적의 성능을 도출해야 한다.
성능 최적화를 하는 데 가장 많은 시간이 소요되는 부분이다.
하이퍼파라미터
1. 진단
: 문제를 진단하는데 사용할 수 있는 것이 모델에 대한 평가이다. 모델이 과적합인지 혹은 다른 원인으로 성능 향상에 문제가 있는지에 대한 인사이트를 얻을 수 있다
가능한 상황들
- train이 test보다 눈에 띄게 좋다면 과적합 의심 -> 규제화로 해결
- train과 test가 모두 성능이 좋지 않다면 과소적합 의심 -> 네트워크 구조 변경, 에포크 수 조정으로 해결
- train이 test를 넘어서는 변곡점 -> 조기 종료를 고려
2. 가중치
: 가중치에 대한 초깃값은 작은 난수를 사용한다. 작은 난수를 선택할때는 오토인코더 같은 비지도 학습을 이용하여 사전 훈련을 진행한 후 지도 학습을 진행하는 것도 방법이다
3. 학습률
: 초기에 매우 크거나 작은 임의의 난수를 선택하여 학습 결과를 조금씩 변경해야 한다. 이때 네트워크의 계층이 많다면 학습률은 높아야 하며, 계층이 적다면 학습률은 작게 설정해야 한다.
4. 활성화 함수
: 활성화 함수를 변경할 때 손실 함수도 함께 변경해야 하는 경우가 많기 때문에 신중해야 한다. 따라서 다루고자 하는 데이터 유형 및 데이터로 어떤 결과를 얻고 싶은지 정확하게 이해하지 못했다면 활성화 함수의 변경은 신중해야 한다. 일반적으로 활성화 함수로 sigmoid나 tanh를 사용했다면 출력층에서는 softmax나 sigmoid를 많이 선택한다.
5. 배치와 에포크
: 큰 에포크와 작은 배치를 사용하는 것이 최근 트렌드이다. 하지만, 적절한 배치 크기를 위해 훈련 데이터셋의 크기와 동일하게 하거나 하나의 배치로 훈련을 시켜 보는 등 다양한 테스트를 진행하는 것이 좋다.
6. 옵티마이저 및 손실 함수
: 옵티마이저는 확률적 경사 하강법을 많이 사용한다. Adam이나 RMSProp 등도 좋은 성능을 보이고 있다. 이것 역시 다양한 옵티마이저와 손실 함수를 적용해 보고 성능이 최고인 것을 선택해야 한다.
7. 네트워크 구성
: 네트워크 토폴로지(topology)라고도 한다. 네트워크 구성을 변경해 가면서 성능을 테스트해야 한다. 예를 들어 하나의 은닉층에 뉴런을 여러 개 포함시키거나(네트워크가 넓게), 네트워크 계층을 늘리되 뉴런 개수는 줄여 본다(네트워크가 깊게). 혹은 두가지를 결합하는 방법으로 최적의 네트워크가 무엇인지 확인한다.
8.1.4 앙상블을 이용한 성능 최적화
앙상블을 이용한 성능 최적화
: 앙상블은 모델 두 개 이상 섞어서 사용하는 것이다
알고리즘 튜닝을 위한 성능 최적화 방법은 하이퍼파라미터에 대한 경우의 수를 모두 고려해야 하기 때문에 모델 훈련이 수십 번에서 수백 번 필요할 수 있다. 따라서 수많은 시행착오를 겪어야 한다.
8.2 하드웨어를 이용한 성능 최적화
딥러닝에서 기존 CPU가 아닌 GPU를 이용할 경우 성능 향상이 가능한 이유를 알아보자.
8.2.1 CPU와 GPU 사용의 차
CPU와 GPU 성능 비교

그래프를 보면 CPU 5개를 동시에 돌려도 GPU 1개보다 성능이 좋지 못하다.
CPU
- 연산을 담당하는 ALU와 명령어를 해석하고 실행하는 컨트롤, 데이터를 담아두는 캐시로 구성되어 있다.
- 명령어가 입력되는 순서대로 데이터를 처리하는 직렬 처리 방식이다.
- CPU는 한 번에 하나의 명령어만 처리하기 때문에 연산을 담당하는 ALU 개수가 많을 필요가 없다.
GPU
- 병렬 처리를 위해 개발되었다.
- 캐시 메모리 비중은 낮고, 연산을 수행하는 ALU 개수가 많아졌다.
- 즉, 연산을 수행하는 많은 ALU로 구성되어 있기 때문에 여러 명령을 동시에 처리하는 병렬 처리 방식에 특화되어 있다.
- 하나의 코어에 ALU 수백~수천 개가 장착되어 있기 때문에 CPU로는 시간이 많이 걸리는 3D 그래픽 작업 등을 빠르게 수행할 수 있다.
CPU vs GPU 구조

CPU vs GPU
- 개별적 코어 속도는 CPU가 훨씬 빠르다.
- CPU가 적합한 분야가 있고, GPU가 적합한 분야가 있다.
- 딥러닝을 예로 들어보자. 파이썬이나 MATLAB처럼 행렬 연산을 많이 사용하는 재귀 연산이 '직렬' 연산을 수행한다. 즉, 3x3 행렬에서 A열이 처리된 후 B열이 처리되고 C열이 처리되는 순차적 연산일 때는 CPU가 적합하다.
- 하지만 역전파처럼 복잡한 미적분은 병렬 연산을 해야 속도가 빨라진다. A, B, C열을 얼마나 동시에 처리하느냐에 따라 계산 시간이 달라지기 때문이다.
- 딥러닝은 데이터를 수백에서 수천만 건까지 다루는데, 여기에서 다룬다는 것은 데이터를 벡터로 변환한 후 연산을 수행한다는 의미이다. 이 때 GPU 사용은 필수이다.
8.2.2 GPU를 이용한 성능 최적화
CUDA(Computed Unified Device Architecture)
: NVIDIA에서 개발한 GPU 개발 툴
- 많은 양의 연산을 동시에 처리할 수 있다.
- 딥러닝, 채굴 같은 수학적 계산에 많이 사용된다.
8.3 하이퍼파라미터를 이용한 성능 최적화
배치 정규화, 드롭아웃, 조기 종료가 있다
8.3.1 배치 정규화를 이용한 성능 최적화
1. 정규화(normalization)
: 데이터 범위를 사용자가 원하는 범위로 제한하는 것

- 예를 들어 이미지 데이터는 픽셀 정보로 0~255 사이의 값을 갖는데, 이를 255로 나누면 0~1.0 사이의 값을 갖게 된다.
- 정규화는 스케일을 조정한다는 의미로 특성 스케일링(feature scaling)이라고도 한다.
- 스케일 조정을 위해 MinMaxScaler() 기법을 사용한다.

2. 규제화(regularization)
: 모델 복잡도를 줄이기 위해 제약을 두는 방법
제약은 데이터가 네트워크에 들어가기 전에 필터를 적용한 것이라고 생각하면 된다.

왼쪽 그림은 필터가 적용되지 않을 경우 모든 데이터가 네트워크에 투입되지만, 오른쪽 그림은 필터로 걸러진 데이터만 네트워크에 투입되어 빠르고 정확한 결과를 얻을 수 있다.
규제를 이용하여 모델 복잡도를 줄이는 방법
- 드롭아웃
- 조기 종료
3. 표준화(standardization)
: 기존 데이터를 평균은 0, 표준 편차는 1인 형태의 데이터로 만드는 방법
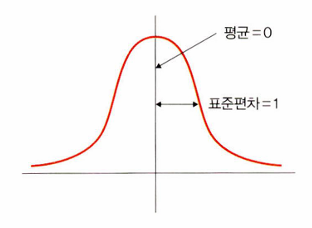
- 표준화 스칼라(standard scaler), z-스코어 정규화(z-score normalization)라고도 한다.
- 평균을 기준으로 얼마나 떨어져 있는지 살펴볼 때 사용한다.
- 데이터 분포가 가우시안 분포를 따를 때 유용한 방법이다.

4. 배치 정규화(batch normalization)
: 기울기 소멸(gradient vanishing)이나 기울기 폭발(gradient exploding) 같은 문제를 해결하기 위한 방법이다.
기울기 소멸과 기울기 폭발
기울기 소멸 : 오차 정보를 역전파시키는 과정에서 기울기가 급격히 0에 가까워져 학습이 되지 않는 현상
기울기 폭발 : 학습 과정에서 기울기가 급격히 커지는 현상

- 논문에 따르면 기울기 소멸과 폭발 원인은 내부 공변량 변화(internal covariance shift) 때문이다.
- 내부 공변량 변화 : 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌는 현상을 의미한다.
- 분산된 분포를 정규분포로 만들기 위해 표준화와 유사한 방식을 미니 배치에 적용하여 평균은 0, 표준편차는 1로 유지하도록 한다.
- 매 단계마다 활성화 함수를 거치면서 데이터셋 분포가 일정해지기 때문에 속도를 향상시킬 수 있다
배치 정규화 수식

- 미니 배치 평균을 구한다.
- 미니 배치의 분산과 표준편차를 구한다.
- 정규화를 수행한다.
- 스케일을 조정한다.
배치 정규화 단점
- 배치 크기가 작을 때는 정규화 값이 기존 값과 다른 방향으로 훈련될 수 있다. 예를 들어 분산이 0이면 정규화 자체가 안 되는 경우가 생길 수 있다.
- RNN은 네트워크 계층별로 미니 정규화를 적용해야 하기 때문에 모델이 더 복잡해지면서 비효율적일 수 있다.
8.3.2 드롭아웃을 이용한 성능 최적화
과적합이 문제인 이유
: 훈련 데이터셋은 실제 데이터셋의 부분 집합이므로 훈련 데이터셋에 대해서는 오류가 감소하지만, 테스트 데이터셋에 대해서는 오류가 증가한다. 어느 순간부터 테스트 데이터셋에 대한 오류가 증가하는데, 이러한 모델을 과적합되어 있다고 한다.
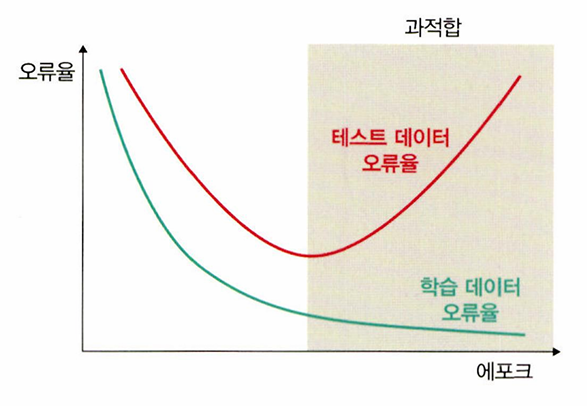
드롭아웃(dropout)
: 훈련할 때 일정 비율의 뉴런만 사용하고, 나머지 뉴런에 해당하는 가중치는 업데이트하지 않는 방법
- 매 단계마다 사용하지 않는 뉴런을 바꾸어 가며 훈련시킨다
- 즉, 노드를 임의로 끄면서 학습하는 방법이다
- 은닉층에 배치된 노드 중 일부를 임의로 끄면서 학습한다
- 꺼진노드는 신호를 전달하지 않으므로 지나친 학습을 방지하는 효과가 생긴다

- 오른쪽에서 일부 노드들은 비활성화되고 남은 노드들로 신호가 연결되는 신경망 형태를 띠고 있다.
- 어떤 노드를 비활성화할지는 학습할 때마다 무작위로 선정되며, 테스트 데이터로 평가할 때는 노드들을 모두 사용하여 출력하되 드롭아웃 비율(노드 삭제 비율)을 곱해서 성능을 평가한다.
- 드롭아웃을 사용하면 훈련 시간이 길어지는 단점이 있지만, 모델 성능을 향상하기 위해 자주 쓰는 방법이다.
배치 정규화와 드롭아웃에 대한 파이토치 예제
class BNNet(nn.Module):
def __init__(self):
super(BNNet, self).__init__()
self.classifier = nn.Sequential(
nn.Linear(784, 48),
nn.BatchNorm1d(48), # 배치 정규화가 적용되는 부분
# 사용되는 파라미터는 특성 개수로 이전 계층의 출력 채널
nn.ReLU(),
nn.Linear(48, 24),
nn.BatchNorm1d(24),
nn.ReLU(),
nn.Linear(24, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x- 배치 정규화를 사용하는 이유는 은닉층에서 학습이 진행될 때마다 입력 분포가 변하면서 가중치가 엉뚱한 방향으로 갱신되는 문제가 종종 발생하기 때문이다.
- 신경망의 층이 깊어질수록 학습할 때 가정했던 입력 분포가 변화하여 엉뚱한 학습이 진행될 수 있는데 배치 정규화를 적용해서 입력 분포를 고르게 맞춰줄 수 있다.

배치 정규화 위치

완전연결층/합성곱층 -> 배치 정규화 -> 활성화 함수
훈련 결과 분석

- 드롭아웃을 적용했을 때의 오차가 더 낮다
- 훈련 횟수가 늘어날수록 파란색 실선은 자주색 점(훈련 데이터셋)들을 찾아가고 있다. -> 이것은 다른 의미로 과적합 현상을 보이고 있는 것
- 초록색 점선 그래프에서는 과적합 현상이 발생하지 않는다
8.3.3 조기 종료를 이용한 성능 최적화
조기 종료(early stopping)
: 훈련 데이터와 별도로 검증 데이터를 준비하고, 매 에포크마다 검증 데이터에 대한 오차를 측정하여 모델의 종료 시점을 제어한다.

- 과적합이 발생하기 전까지 학습에 대한 오차와 검증에 대한 오차 모두 감소하지만, 과적합이 발생하면 훈련 데이터셋에 대한 오차는 감소하는 반면 검증 데이터셋에 대한 오차는 증가한다.
- 조기종료는 검증 데이터셋에 대한 오차가 증가하는 시점에서 학습을 멈추도록 조정한다.
- 학습을 언제 종료시킬지 결정할 뿐이지 최고의 성능을 갖는 모델을 보장하지는 않는다.
학습률 감소(learning rate decay)
: 학습이 진행되는 과정에서 학습률을 조금씩 낮추어 주는 성능 튜닝 기법
검증 데이터셋의 손실 또는 성능 지표를 사용하여 모델의 학습률을 조절한다.
- 학습률 스케줄러(learning rate scheduler)라는 것을 이용한다.
- 주어진 'patience' 횟수만큼 검증 데이터셋에 대한 오차 감소가 없으면 역시 주어진 'factor'만큼 학습률을 감소시켜서 모델 학습의 최적화가 가능하도록 도와준다.
※ patience : 학습률을 감소시키기 전에 성능이 개선되지 않는 epoch의 수
일반적으로 모델의 성능이 개선되지 않는 epoch의 수가 patience보다 크면, learning rate가 감소된다.
patience가 클수록, 모델은 더 많은 epoch 동안 성능이 개선되지 않아야 하므로, 학습률을 감소시키는 빈도가 줄어든다. (patience 횟수만큼 참는다)
self.lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer,
mode='min',
patience=self.patience,
factor=self.factor,
min_lr=self.min_lr,
verbose=True
)- lr_scheduler.ReduceLROnPlateau : ReduceLROnPlateau는 검증 데이터셋에 대한 오차의 변동이 없으면 학습률을 factor 배로 감소시킨다.
- optimizer : 가중치를 갱신시키는 부분. 여기서는 Adam을 사용한다.
- mode : 언제 학습률을 조정할지에 대한 기준이 되는 값이다. 만약 검증 데이터셋에 대한 오차를 기준으로 사용하면 오차가 더 이상 감소되지 않을 때 학습률을 조정하게 된다. 이때 오차 값이 최소(min)가 되어야 하는지, 최대(max)가 되어야 하는지 알려 주는 파라미터가 mode이다. 예를 들어 학습률 조정의 기준이 되는 값을 모델의 정확도로 사용하면 값이 클수록 좋기 때문에 max를 지정하고, 모델의 오차로 적용한 경우 작을수록 좋기 때문에 min을 지정한다.
- patience : 학습률을 업데이트하기 전에 몇 번의 epoch를 기다려야 하는지 결정하는 것
- factor : 학습률을 얼마나 감소시킬지 지정하는 파라미터이다. 새로운 학습률은 기존 학습률 * factor가 된다. 예를 들어 현재 학습률이 0.01이고 factor가 0.5일 때, 콜백 함수가 실행된다면 그다음 학습률은 0.005가 된다.
- min_lr : 학습률의 하한선을 지정한다. 예를 들어 현재 학습률이 0.1이고 factor가 0.5, min_lr이 0.03이라면 첫 번째로 콜백 함수가 적용될 때 학습률의 하한선 값은 0.03 * (0.1 * 0.5)처럼 계산된다.
- verbose : 조기 종료의 시작과 끝을 출력하기 위해 사용한다. 1로 설정할 경우 조기 종료가 적용되면 적용되었다고 화면에 출력되지만, 0으로 설정할 경우 아무런 출력 없이 학습을 종료한다.
콜백 함수(callback)
: 개발자는 단지 함수 등록만 하고 특정 이벤트 발생에 의해 함수를 호출하고 처리하도록 하는 것
- 개발자가 명시적으로 함수를 호출하지 않는다.
- 동기적(synchronous) 함수와 비동기적(asynchronous) 함수가 있다.
- 동기적 함수는 코드가 위에서 아래로, 왼쪽에서 오른쪽으로 순차적으로 실행되는 함수이며, 비동기 함수는 병렬 처리와 같다고 이해하면 된다.
- 비동기 함수 : 어떤 코드를 실행했을 때 상당한 시간을 기다려야 하는 경우 해당 코드가 완료될 때까지 기다리는 것이 아닌 다른 코드가 먼저 처리되도록 하는 것
모델 학습에 대한 출력 결과
1. 어떤 인수도 적용하지 않았을 때


정확도 - 위아래로 많은 변동이 있다.
오차 - 에포크 10 이후부터 검증 데이터셋에 대한 오차가 미세한 차이로 우상향한다. (과적합) 적절한 훈련을 계속하려면 학습률 값을 줄여야 한다.
2. 학습률 감소에 대한 인수가 적용되었을 때
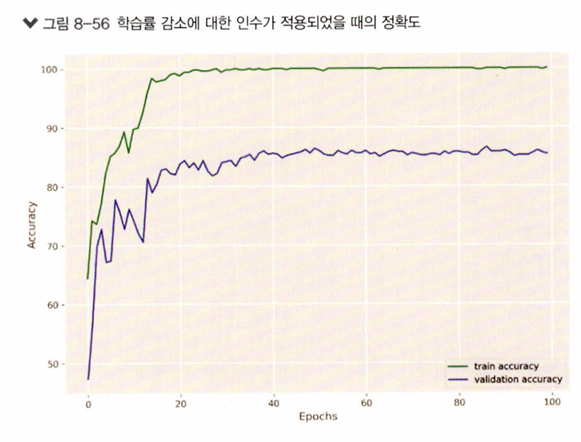

정확도 - 완만한 곡선 형태를 보여준다. 훈련이 종료된 시점의 검증 데이터셋에 대한 정확도도 높게 나탖나고 있다.
오차 - 그래프가 우상향하는 현상도 없어졌다. 하지만, 검증 데이터셋에 대한 오차가 에포크 20 정도에서도 정체되기 시작한다. 즉, 에포크를 30 정도만 수행해도 모델 훈련에 여전히 좋은 결과를 얻을 수 있을 것이다.
3. 조기 종료에 대한 인수가 적용되었을 때


5번째 에포크부터 조기 종료가 수행되고 있기 때문에 실제로 학습은 4번째 에포크까지만 수행되었다.
정확도 - 검증 데이터셋에 대한 정확도가 위아래로 오가면서 불안정한 결과를 출력하고 있다.
오차 - 많이 낮아졌다.
※ 조기종료가 항상 성능에 좋은 영향을 미치는 것은 아니다.
조기 종료로 인해 모델이 제대로 학습하지 못할 수 있다. 따라서 그래프가 의미하는 내용을 잘 이해하고 적절한 성능 향상 방안을 적용하는 것이 중요하다.
※ 정확도만 보고 조기 종료가 효과가 없다고 판단할 순 없다.
※ 학습률 스케줄러를 이용한 학습률 조정 기법과 조기 종료가 모델 성능을 향상시키는데는 도움이 된다.
조기 종료의 경우에는 성능 향상보다는 자원의 효율화라고 보는 것이 정확하다.
모든 모델에 일괄적으로 적용하는 것이 아닌, 기존의 출력된 그래프를 해석해서 어떤 성능 기법을 적용할지 결정하는 것이 중요하다.
※ p.469
iteration 관련 코드 수정
dataiter = iter(trainloader)
images, labels = dataiter.next() # 변경전dataiter = iter(trainloader)
images, labels = next(dataiter) #변경후
※ p.470
- torchvision.datasets 이미지 형태 : [배치 크기, 채널, 높이, 너비]
- matplotlib.imshow() 이미지 형태 : [배치 크기, 높이, 너비, 채널]
-> transpose()를 적용하여 차원 순서를 맞춰줘야 한다.
def imshow(img, title):
plt.figure(figsize = (batch_size * 4, 4)) # figure 사이즈 지정
plt.axis('off') # 시각화 시 축 표시 x
plt.imshow(np.transpose(img, (1,2,0))) # 시각화 시에는 데이터 형태를 [batch_size, height, width, channel]로 바꿔줘야 함
# 따라서 시각화 직전에 바꾸고 시각화(imshow, image show)
plt.title(title) # 제목
plt.show() # 시각화 결과 출력(실제 화면에 보이도록)
def show_batch_images(dataloader):
images, labels = next(iter(dataloader)) # 이미지 크기 (4, 1, 28, 28)(배치, 채널, 높이, 너비)
img = torchvision.utils.make_grid(images) # 그리드 형태로 출력
imshow(img, title=[str(x.item()) for x in labels]) # imshow 함수 사용해 (4, 28, 28, 1)(배치, 높이, 너비, 채널)로 변경
return images, labels
imshow() 함수를 호출하면 plt.imshow() 직전에 np.transpose() 함수를 거치면서 데이터 차원 순서가 [batch_size, height, width, channel] = [4, 28, 28, 1]로 변경된다.
'Deep Learning > Pytorch' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 10장. 임베딩 -(1) (0) | 2024.05.31 |
|---|---|
| [딥러닝 파이토치 교과서] 9장. 자연어 전처리 (0) | 2024.05.16 |
| [딥러닝 파이토치 교과서] 7장. 시계열 분석 -(2) (0) | 2024.05.14 |
| [딥러닝 파이토치 교과서] 7장. 시계열 분석 -(1) (0) | 2024.05.10 |
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(2) (1) | 2024.05.03 |



