
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 이진 탐색
- 정렬
- 머신러닝
- pytorch
- 삽입정렬
- rnn
- 그리디
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 스택
- 알고리즘
- 인공지능
- BFS
- 선형대수
- DFS
- Machine Learning
- 계수정렬
- 재귀함수
- GRU
- AI
- 딥러닝
- 큐
- LSTM
- 다이나믹 프로그래밍
- RESNET
- 최단 경로
- 선택정렬
- 퀵정렬
- Today
- Total
hyeonzzz's Tech Blog
[boostcourse] 3. Seg&Det - Object Detection 본문
Object Detection
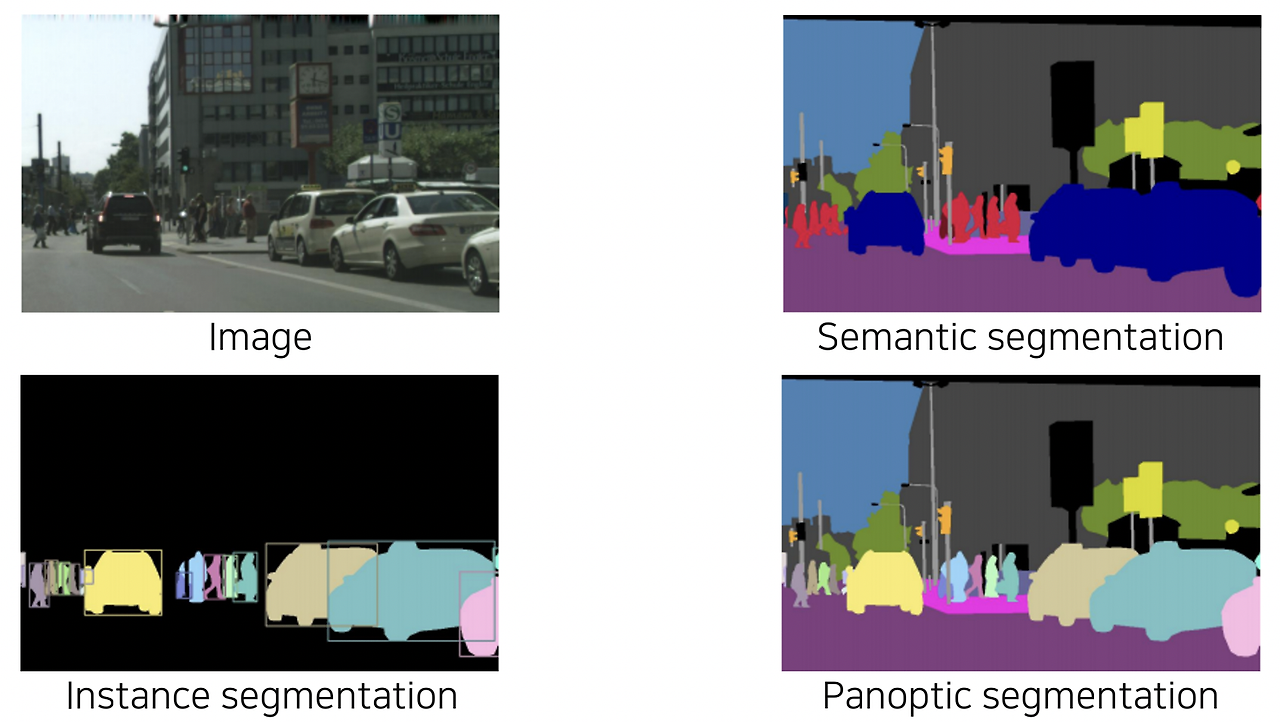
Computer Vision 분야에는 가장 간단한 Image Classification부터 Semantic Segmentation, 그리고 더 발전된 task인 Instance Segmentation, Panoptic Segmentation등의 task들이 있습니다.
- semantic segmentation - 사람은 같은 색으로 mapping 되었음
- instance segmentation ( ⊂ panoptic segmentation ) - 같은 사람일지라도 다른 개체로 구분되었음
이때 각 개체들을 구분하기 위해서는 본 강의에서 소개할 Object Detection 기술이 필요합니다. 따라서 Object Detection은 Semantic Segmentation을 보다 근본적인 scene understanding 기술이라고 보시면 될 것 같습니다.
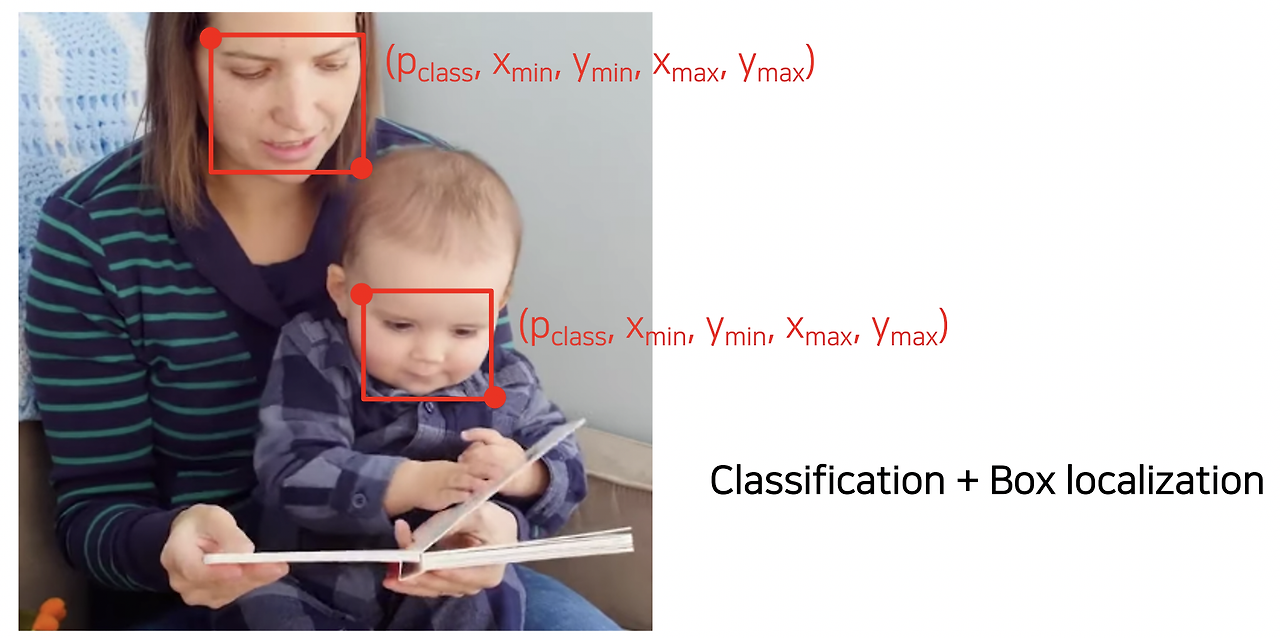
Object Detection
: classification과 bounding box를 동시에 예측하는 문제
위의 그림과 같이 특정 물체의 위치를 bounding box의 형태로 예측하고, 해당 물체의 클래스까지 분류해내는 task입니다.

이렇게 찾은 물체의 위치 정보와 카테고리 정보는 다양한 분야에 활용될 수 있습니다.
대표적인 예시로 자율주행 기술, OCR(Optical Character Recognition) 등을 생각해볼 수 있습니다. 그만큼 Object Detection의 산업 가치가 매우 크나고 볼 수 있습니다.
최근의 Object Detection은 two-stage detector와 single-stage detector로 나뉘어 빠르게 발전하고 있습니다. 먼저 R-CNN 계열의 two-stage detector들을 살펴보도록 하겠습니다.
1. Two-stage Detector (R-CNN family)
1) R-CNN

본격적으로 첫 번째 딥러닝 기반의 접근으로 Object Detection을 해결해낸 R-CNN에 대해 위의 그림과 함께 살펴보겠습니다. 기본적인 이미지 classification을 최대한 잘 활용하기 위해 간단한 프로세스를 가집니다.
<R-CNN 프로세스>
- 먼저 Selective search 등의 huristic한 방법을 통해 region proposal을 구해냅니다. 참고로 R-CNN에서는 약 2천개 이하로 구했다고 합니다.
- 이렇게 얻은 region들을 CNN classification에 활용할 수 있도록 적절한 사이즈로 warping해줍니다. 이 warped region을 CNN으로 feature를 추출합니다.
- SVM으로 classification하여 결과적으로 region에 대한 classification을 수행합니다.
<단점>
- reigion proposal 하나하나 마다 classification을 수행해주어야 하기 때문에 속도가 매우 느립니다.
- end-to-end network가 아니기 때문에 학습을 통한 성능 향상이 제한되어 있다는 한계가 있습니다. (region proposal 하나하나마다 모델에 넣어 프로세싱 해야함. selective search같은 별도의 핸드디자인된 알고리즘을 사용함.)
2) Fast R-CNN

이렇게 R-CNN이 갖는 느린 속도를 개선하고자 동일한 저자들이 Fast R-CNN 구조를 제안하였습니다. 이 방법에서의 핵심은 이미지 전체에 대한 feature를 한번에 추출하고, 이를 재활용하여 여러 object들을 탐지할 수 있도록 한 것입니다.
<Fast R-CNN 프로세스>
- 먼저 convolution layer를 통해 입력 이미지 전체의 feature map을 추출합니다. (이때 feature map은 텐서의 형태 h, w, c를 가집니다. fully-convolutional한 구조의 네트워크는 입력 사이즈에 상관없이 feature map을 추출할 수 있습니다.)
- 그 이후 이러한 feature map을 여러번 반복하여 재활용하기 위해 ROI(Region Of Interest) Pooling 기법을 사용합니다. 바운딩박스가 주어지면 ROI에 해당하는 feature만을 추출합니다. 즉 전체 feature map에서 ROI에 해당하는 부분만 추출하는 것입니다. (ROI - region proposal이 제시한 물체의 후보 위치들을 의미)
- 이후 이를 고정된 사이즈로 resampling 합니다. 이를 기반으로 FC layer를 거쳐 region에 대한 classification을 수행하고, 더 정확한 bounding box를 얻기 위해 bounding box regression을 수행합니다.
이러한 방법을 통해 R-CNN에 비해 약 18배 빠른 속도를 달성할 수 있었지만, 여전히 region proposal을 위해 huristic한 방법을 사용하고 있었기 때문에 (selective search같은 별도의 알고리즘 사용)성능을 크게 향상시킬 순 없었습니다.
3) Faster R-CNN
이러한 흐름을 고려할 때 Faster R-CNN에서는 region proposal을 개선했다는 것을 예측할 수 있겠죠? Faster R-CNN에서는 region proposal까지 neural network 기반의 방법을 활용하여 최초의 end-to-end object detection 구조를 제안했습니다.

IoU(Intersection over Union)
: 두 영역의 overlap을 측정하는 지표로써, 중복되는 영역의 넓이를 두 영역을 합한 영역의 넓이로 나눠준 값
즉 이 값이 높을 수록 두 영역이 잘 정합한다고 볼 수 있습니다.

그럼 Faster R-CNN에서 사용한 region proposal 방식을 anchor box라는 개념과 함께 알아보도록 하겠습니다.
<Anchor box>
:각 위치에서 발생할 것 같은 box들을 미리 정의해놓은 후보군입니다. 비율과 스케일이 다른 영역을 각 위치마다 미리 정해놓고 쓰는 것입니다. Faster R-CNN에서는 서로 다른 scale 3개와 서로 다른 비율 3개, 총 9개의 anchor box를 사용합니다. ground truth가 0.7을 넘는 bounding box가 positive가 되고 나머지는 negative가 됩니다.

Faster R-CNN에서 가장 핵심적인 변화는 기존의 time-consuming selective search 방법이 아닌 Region Proposal Network (RPN) 모듈을 통해 region proposal을 수행한다는 점입니다.
- 영상 하나에서부터 공유되는 feature map을 미리 뽑아놓습니다.
- RPN에서 region proposal을 여러개 제안하게 됩니다.
- region proposal을 이용해서 RoI pooling을 실시합니다.
- classification과 bounding box regression을 수행합니다.
<RPN 구조>

Sliding window 방식으로 각 픽셀의 위치마다 k개의 anchor box를 고려합니다. Anchor box는 각 픽셀 위치에서 발생할 확률이 높은 bounding box들을 사전에 정의해둔 일종의 후보군이라고 볼 수 있으며, Faster R-CNN에서는 서로 다른 크기와 비율을 가진 9개의 anchor box를 사용했습니다.
구체적으로 anchor box를 고려하는 방식을 알아보겠습니다. 먼저 각 픽셀 위치에서 256 차원의 feature 벡터를 추출합니다. 이 벡터를 입력으로 classfication layer를 거쳐 object인지 object가 아닌지를 판별하는 2k개의 classification 점수를 출력하고, regression layer를 거쳐 4k개의 좌표값을 출력합니다. (-> 왜 box를 다시 regression할까? 적당한 양의 anchor box를 미리 만들어 놓고 더 정교한 위치는 regression 문제로 다시 풀자는 것 - 분할정복) objectness classifier는 classification loss (CrossEntropyLoss같은)를 쓰고 box coordinate regression에는 regression loss를 사용하는데 이 두 Loss는 RPN을 위한 것이고, 전체 ROI에 대한 classification loss는 따로 추가되어 end-to-end로 계산됩니다.

이렇게 RPN을 활용하게 되면 threshold 값을 통과하는 region 중에서 중복되고 겹치는 부분이 많은 region이 많이 발생하게 됩니다. 이러한 region을 삭제해주기 위해 위와 같이 Non-Maximum Suppersion (NMS)를 사용해줍니다. 그 과정의 위의 그림과 같고, 딥러닝 이전부터 세대에서부터 대부분의 object detection 알고리즘에 활용되었던 기법입니다.
4) R-CNN family 요약

R-CNN
- Region proposal을 별도의 알고리즘으로 사용한 것이 특징
- CNN부분도 target task에 대해서 학습하지 않고 미리 pre-trained되어 있었음
- 마지막 부분에 간단한 classifier을 통해서 파인튜닝을 했음
- 딥러닝의 장점을 다 활용하지 못함
Fast R-CNN
- RoI pooling을 통해 하나의 feature로부터 여러 물체를 탐지가능하도록 했음 -> CNN부분을 학습가능하도록 만듬
- 여전히 Region proposal부분이 학습가능하지 않음
Faster R-CNN
- Region proposal부분마저도 RPN이라는 네트워크를 통해 학습되도록 함
- 전체 프로세스가 end-to-end로 학습가능하도록 설계함
- regression과 classifier의 joint Loss가 backpropagation을 통해 RPN과 feature모두 학습되게 함 -> taget task에 oriented된 feature를 잘 학습할 수 있는 첫번째 구조
2. Single-stage Detector

Single-stage detector의 경우 정확도를 어느정도 포기하더라도 빠르게 object detection을 수행하여 실시간으로 활용할 수 있도록 하는 것에 집중한 구조입니다. 이에 따라 region proposal 과정을 수행하지 않고 bonding box regression과 classification을 수행하기 때문에 빠른 실행시간과 간단한 구조를 가집니다.
1) YOLO

<YOLO 동작방식>
- 입력 이미지는 SxS의 그리드로 나눕니다.
- 각 그리드에 대해서 B개의 box 즉, 4개의 bounding box의 좌표와 그에 대한 confidence score, 그리고 classification score를 예측합니다. (이전에 봤던 anchor box와 유사한 개념. 미리 각 위치의 bounding box 형태로 B개를 정해놓고 이것들에 대해서 더 정교한 box로 regression해주는 부분도 포함된 것)
- 최종 결과는 이전과 마찬가지로 NMS(Non-maximum Suppression)를 통해 정리된 bounding box만을 출력하게 됩니다.
- 학습시킬때도 Fast R-CNN에서 사용했던 방식과 동일합니다. GT와 매치된 anchor box들을 positive로 간주하고 학습 레이블을 positive로 걸어줍니다.
<YOLO 구조>

일반 CNN의 구성과 유사합니다. 이때 최종 출력이 7x7(해상도)x30(채널)인 것을 확인할 수 있는데, 이는 YOLO에서 최종적으로 예측하는 것이 5(4개의 좌표값 + confidence score)*B(anchor box의 개수, 2) + C(class의 개수, 20)이라 각 위치마다 30 차원의 벡터를 출력하는 것입니다. 그리드를 S x S로 나눈다고 했는데 여기서 S가 7이 되는 것입니다. S는 convolution layer에 의해서 마지막 layer의 해상도로 결정됩니다.
YOLO는 맨 마지막 layer에서 한번만 prediction하기 때문에 localization 정확도가 떨어지는 결과를 보여줍니다. 이를 보완하기 위해 SSD가 등장했습니다.
2) SSD (Single Shot MultiBox Detector)
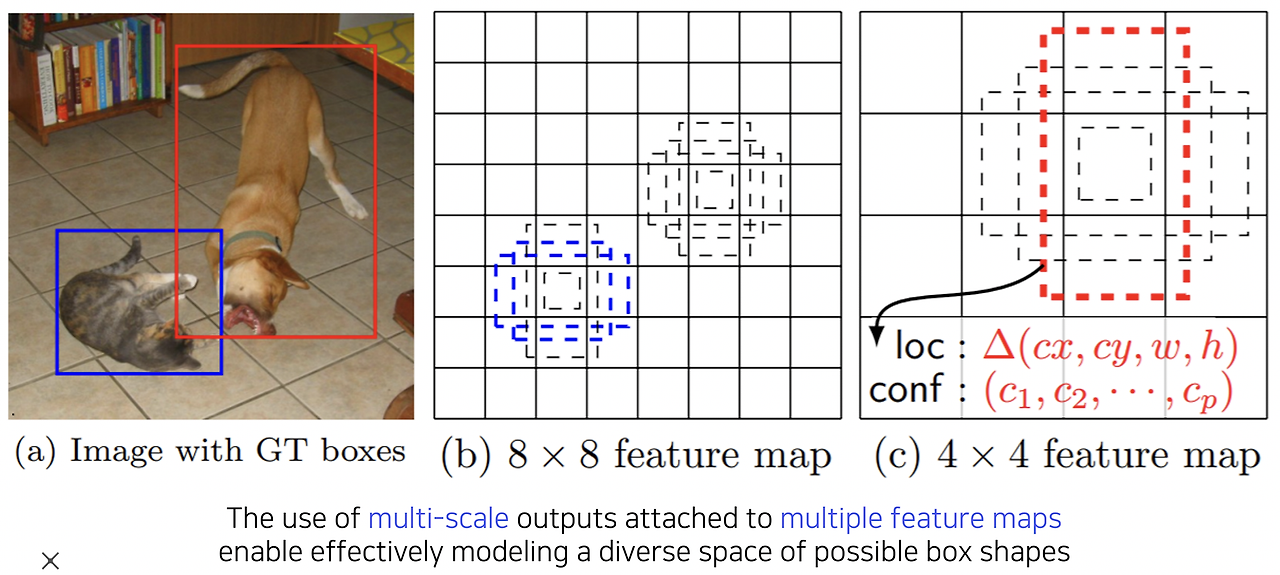
SSD는 multi-scale object들을 더욱 잘 처리하기 위해 중간 feature들을 잘 고려한 bounding box를 출력할 수 있도록 동작합니다. 위 그림과 같이 8x8 feature map에서의 bounding box와 4x4 feature map에서의 bounding box의 사이즈를 비교해보면 각 feature map마다 해상도에 적절한 bounding box 크기와 이에 대한 결과를 예측할 수 있도록 만들었습니다.

VGG를 backbone으로 해서 Conv4 블럭의 중간 feature map 출력에서부터 최종 결과들을 출력하게끔 classifier가 붙어있습니다. 각 scale마다 object detection결과를 출력하도록 해서 다양한 scale의 object들에 대해서 잘 대응할 수 있도록 했습니다. (
Conv4 블럭에서부터 bounding box를 출력하여 multi-scale object에 대한 bounding box에 잘 대응하기 위한 구조를 가지는 것을 확인할 수 있습니다)
class수와 함께 4개의 coordinate 정보를 출력해야하기 때문에 class수 + 4가 되고, bounding box 4개 또는 6개를 쓴다는 의미로 4 또는 6을 곱해줍니다.
최종적으로 8732라는 숫자를 살펴보면, 각 위치마다 각 레이어 마다 몇 개의 anchor box를 활용하는지 계산해보면 위와 같이 8732개의 anchor box가 결과값으로 나오는 것을 확인할 수 있습니다. 이를 통해 YOLO보다 더 좋은 성능을 보여주면서도 더 빠른 속도를 보여주는 것을 확인할 수 있습니다.
3. Single-stage Detector vs Two-stage Detector
<class imbalance 문제>
Single-stage detector의 경우 ROI pooling이 없기 때문에 모든 영역에서 loss가 계산되고 일정 gradient가 발생합니다. 이는 class imbalance 문제로 이어지는데, 일반적으로 이미지를 고려했을 때 positive sample에 해당하는 물체의 영역에 비해 물체가 아닌 negative sample의 영역(배경)이 훨씬 크기 때문입니다.
<Focal Loss>

이런 불균형 문제를 완화하기 위해 cross-entropy loss의 확장된 개념이라고 볼 수 있는 focal loss가 제안되었습니다. 그 식을 비교하면 위와 같습니다. γ값에 따라 함수의 형태가 결정되는 모습을 그래프에서 확인할 수 있습니다. γ=0 인 경우는 CrossEntropy이고 true class에 대한 score가 높게 나와서 정답을 잘 맞추는 영역을 보면 낮은 loss값을 반환하고 맞추지 못하면 큰 loss값을 반환합니다.
focal loss 의 경우 확률 term을 붙여 주어서 모델이 잘 예측하고 있는 클래스에 대해서는 완곡한 loss 값을 주고, 잘 예측하지 못하고 있는 클래스에 대해서는 샤프한 loss값을 주는 역할을 합니다. γ값에 따라 휘는 각도가 바뀌게 되는데 오답일때는 γ 가 큰 경우에 더 작은 loss를 갖는데 이때 잘못 해석할 수 있습니다. 정답을 맞추지 못했을 때 더 sharp한 gradient를 가져 큰 영향을 발휘하게 됩니다.
따라서 focal loss를 사용할 경우, cross-entropy loss에 비해 class imbalance 문제를 효과적으로 해결해줄 수 있는 것입니다.
RetinaNet
<Featured Pyramid Network (FPN)>

동일한 논문에서 Featured Pyramid Network (FPN) 구조도 제안합니다.
- 이전에 다뤘던 U-Net과 매우 비슷한 방식으로 low-level의 특징과 high-level의 특징을 잘 고려하면서도 multi-scale object를 잘 탐지하기 위해 제안된 구조입니다.
- U-Net과는 다르게 concatenation이 아니라 합해주는 방식을 취하고, classification head와 box head가 따로 구성되어있어 별도로 각각을 수행해줍니다. 이 구조를 모두 합하여 RetinaNet이라고 명명했습니다.
- RetinaNet은 SSD와 비슷한 속도를 보이며, 훨씬 더 높은 성능을 보여주었습니다.
4. Detection with Transformer
최근 연구의 큰 흐름 중 하나가 NLP 분야에서 큰 성공을 거둔 Transformer 구조를 computer vision 분야에서 활용할지에 대한 연구입니다.
DETR
: Transformer를 object detection에 적용한 사례
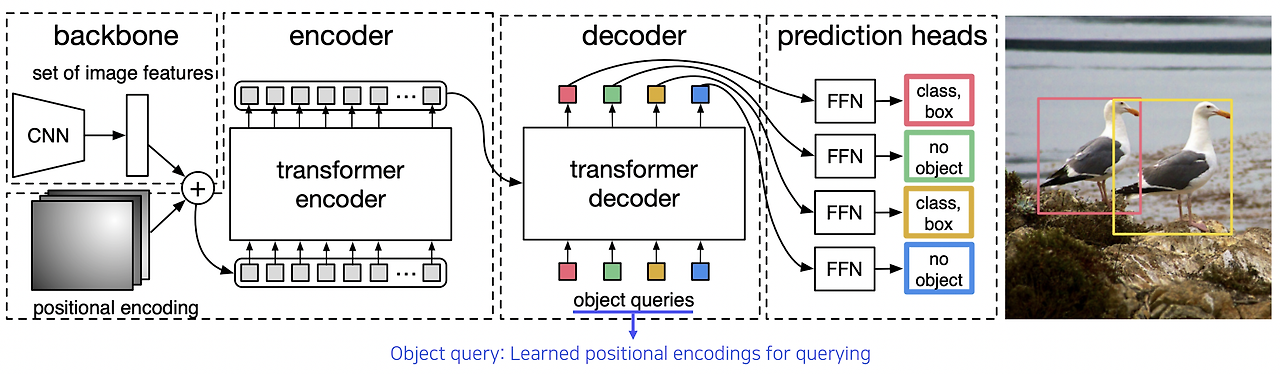
기본적인 구조는 위와 같습니다.
- 먼저 CNN을 통해 입력 이미지의 특징을 추출하고 positional encoding과 함께 더하여 transformer encoder의 입력 토큰으로 넣어줍니다.
- Encoder의 출력으로 얻은 임베딩을 transformer decoder에서 attention 계산시 활용하고, decoder의 입력으로는 object query를 사용합니다. (-> transformer에게 위치에 해당하는 object가 뭔지 질의합니다) 이때 object query는 querying을 위해 사전에 학습된 positional encoding입니다.
- 이후 Transformer decoder가 입력된 object query에 해당하는 object가 무엇인지에 대한 정보를 출력하며, 그 정보를 prediction heads(FFN)을 거쳐 최종적으로 어떤 object인지, 그리고 object가 있다면 그 bounding box의 위치까지 출력하는 구조입니다.
영상 전체의 위치를 질의로 하나하나씩 넣어주는 것입니다. 응답을 detection구조로 사용합니다. object query를 넣어줄 때 무작정 넣어주는 것이 아니라 하나의 이미지에서 최대 N개의 위치에서 object가 가능하다는 maximum 값을 미리 넣어줍니다.
5. Further reading

- detection bounding box를 regression하지 말고 다른 형태의 데이터 구조로 탐지가능한지에 대한 연구
- 물체의 중심점을 대신 찾는다던지, 왼쪽 위와 오른쪽 아래의 양 끝점을 찾는다던지 등으로 box를 곧바로 regression하는 것일 피해 효율적인 계산을 하는 연구
- CornerNet / Center Net
'Deep Learning > CV' 카테고리의 다른 글
| [boostcourse] CNN Visualization (2) : 시각화 방법 (0) | 2024.06.18 |
|---|---|
| [boostcourse] CNN Visualization (1) : 동작 원리 (0) | 2024.06.17 |
| [boostcourse] 3. Seg&Det - Semantic Segmentation (0) | 2024.06.17 |
| [boostcourse] 2. 컴퓨터 비전과 딥러닝 - 영상 인식의 이해 (2) | 2024.06.12 |
| [boostcourse] 2. 컴퓨터 비전과 딥러닝 - 데이터 부족 문제 완화 (1) | 2024.06.11 |



