
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 선형대수
- DFS
- 큐
- 이진 탐색
- rnn
- 인공지능
- 스택
- 딥러닝
- 알고리즘
- 머신러닝
- 선택정렬
- 최단 경로
- AI
- LSTM
- BFS
- 퀵정렬
- 삽입정렬
- 정렬
- pytorch
- 다이나믹 프로그래밍
- Machine Learning
- 계수정렬
- GRU
- 그리디
- RESNET
- 재귀함수
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- Today
- Total
hyeonzzz's Tech Blog
[boostcourse] CNN Visualization (2) : 시각화 방법 본문
CNN Visualization (2) : 시각화 방법
Analysis of Model Behaviors
모델의 행동 방식 및 특성을 분석하는 방법에 대해 알아보도록 하겠습니다.
1. Embedding Feature Analysis - 모델의 embedding feature를 분석하는 방법

예제 이미지를 통해 시각화하는 방법입니다. Nearest-Neighbor 방식을 활용하는데, 구체적으로 query image를 입력했을 때 DB 내에서 query image와 유사한 이미지를 얻은 방식으로 구현됩니다.
예를 들어 코끼리에 대한 이미지를 입력했을 때, 유사한 코끼리 이미지가 나열되는 것을 미루어 보아 embedding space내에서 의미론적으로 유사한 이미지끼리 군집을 이루고 있다는 것을 확인할 수 있습니다.
위 이미지의 파란색 박스 부분을 보면, 동일한 개 이미지더라도 다른 자세를 취하고 있기 때문에 이미지를 벡터 값으로 비교하면 매우 상이할 것이란 것을 알 수 있습니다. 허나 query image에 따라 적절하게 반환되는 것을 보면 확실히 물체의 의미나 개념을 이해하여 군집화되어있다는 것을 알 수 있습니다.
<동작 방법>
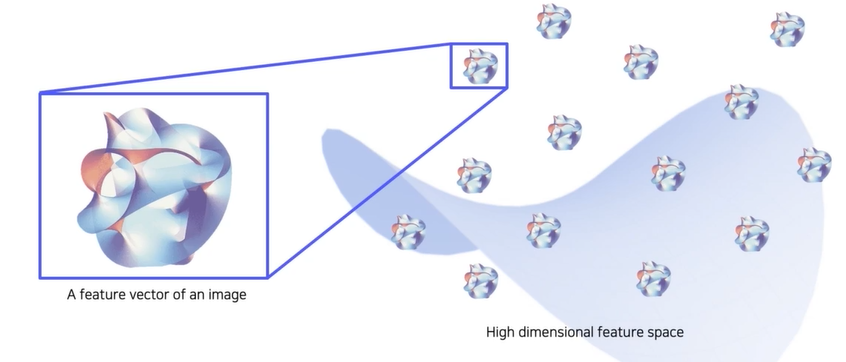
우리가 활용할 embedding space를 표현하면 돌멩이같은 것들이 고차원 공간에 있는 각각의 embedding feature 벡터들을 표현한 것입니다. 각각의 벡터들에 해당하는 영상들이 존재합니다.
실제 구현에서는 미리 학습된 neural network를 준비하고 뒤에서 두번째 FC layer에서 feature를 추출할 수 있도록 준비합니다.

query 영상을 넣어주면 특징이 추출되고, 추출된 특징이 고차원 공간 어딘가에 위치합니다. 영상을 넣을 때마다 feature space의 각 위치에 특징들을 위치시킬 수 있습니다.

모두 뽑아놓은 데이터의 feature들은 고차원 공간상에 존재하고 있고 DB에 저장됩니다. DB에 저장된 feature들은 원래의 영상과 연결되어 있습니다. 위의 그림에서 빨간색 돌멩이들은 아직 영상과 관련이 없고 질의 영상(test하고싶은 영상)을 넣었을 때 mapping되는 feature들을 미리 표시해놓은 것 입니다.

이번엔 질의 영상을 넣어서 특징을 뽑습니다. feature와 거리가 가까운 영상을 뽑아서 return 해주면 embedding vector를 통해서 주변 예제를 분석할 수 있습니다. 한 영상의 근처에 feature vector들이 있었을 것이고, 근처에 있다는 것을 알기 때문에 이것들과 연관된 original DB에서의 이미지들을 찾아서 가져옵니다.

이렇게 예제 이미지를 기반으로 전반적인 경향성을 파악하는 방법을 살펴보았는데요. 이는 전체적인 그림을 한번에 확인할 수 없다는 한계를 가집니다. 따라서 이번에는 전체적인 그림을 한번에 확인할 수 있는 시각화 방법을 소개하도록 하겠습니다. 사실 앞서 살펴보았던 embedding vector는 사람이 쉽게 파악하기 어려울 정도의 고차원 벡터입니다. 따라서 이를 사람이 쉽게 파악할 수 있도록 차원 축소를 통해 3차원 벡터로 만들어 시각화해보겠습니다.
2. t-SNE - 차원 축소를 통해 분포를 쉽게 확인하는 방법

본 강의에서 동작 원리에 대해서 구체적으로 다루진 않겠지만, 워낙 유명한 방법인 만큼 직접 자료를 찾아 스스로 학습해보시는 것을 권장드립니다.
위 그림에서 확인할 수 있는 예시는 0-9까지의 숫자 이미지로 구성된 MNIST 데이터의 특징 벡터를 t-SNE를 사용하여 저차원 벡터로 mapping한 결과입니다. 각 클래스마다 색깔 별로 구분하고 있으며, 확인해보면 몇몇의 아웃라이어들을 제외하고 클래스에 따라 군집화된 결과를 확인할 수 있습니다.
또한 클래스간의 분포도를 보면 3과 8과 5가 분포가 맞닿아있다는 것으로 보아 이 클래스를 유사하게 보고 있음을 알 수 있습니다.
2. Activation Investigation - 중간 layer와 높은 layer를 해석하는 클래스의 해석 방법

layer의 activation을 분석함으로써 모델의 특성을 파악하는 방법입니다.
위의 예시는 각각 AlexNet conv5 layer의 138번째 채널, 53번째 채널의 activation을 적절한 값으로 thresholding하여 mask를 만들고, 이를 원본 이미지에 overlay하면 위와 같은 결과를 얻을 수 있습니다.
각 activation 채널이 hidden node가 되는데 이를 통해 각 layer의 hidden node들의 역할(ex. 얼굴을 탐지하는 혹은 계단을 탐지하는 역할 등)을 파악할 수 있습니다. 또한 CNN의 hidden unit들이 각각 간단한 얼굴 detection, 손 detection, 계단 detection 등을 다층으로 쌓아서 이것들의 조합을 통해 물체를 인식함을 알 수 있습니다.
3. Activation Investigation - layer activation에서 가장 큰 값을 가지는 patch의 위치를 기반으로 분석

구체적으로 이미지를 입력시켜 특정 레이어의 activation map을 구하고, activation map에서 가장 큰 값을 가지는 patch의 위치 정보를 저장합니다. 입력한 이미지에서 그 위치에 해당하는 부분을 잘라서 확인해보면 위의 결과와 같이 layer의 역할(ex. 강아지의 눈 혹은 코 등 검정색 동그란 부분을 탐지하는 역할 등)을 추정해볼 수 있습니다.
이 방법은 high level보다는 mid level을 분석하는데 적합합니다. 왜냐하면 국부적인 patch만 보게 되기 때문에 전반적인 큰 그림을 보기보다는 중간 그림을 보는데 적합합니다.
<동작 방법>
- 분석하고자 하는 특정 layer을 정합니다.
- 예제 데이터를 backbone 네트워크에 넣어서 각 layer의 activation을 뽑습니다. 그 다음 우리가 뽑고싶던 channel의 activation을 저장합니다.
- 저장된 채널의 activation 값 중에서 가장 큰 값을 갖는 위치를 파악하고, 해당 위치의 입력 도메인 위치에서의 receptive field를 계산해 해당 patch를 뜯어옵니다.
- 이렇게 각 hidden node별로 나열하면 hidden layer가 어떤 역할을 하는지 알 수 있습니다.
4. Activation Investigation - 예제 데이터를 사용하지 않고 네트워크가 내재하고 있는 이미지가 어떤 것인지 분석하는 방법

지금까지는 소개한 방법들에서는 activation을 분석하기 위해 데이터에서 추출한 특정 이미지를 사용했었는데요. 지금 소개할 class visualization은 데이터를 사용하지 않고 네트워크에 내재되어 있는 정보를 시각화하는 방법을 소개합니다.
가령 위의 그림과 같이 "새"로 분류하기 위해서 새의 형상을 띄고 있는 무언가와 나뭇가지 비슷한 무언가를 집중하여 탐지하고 있는 것을 확인할 수 있고, "개"로 분류하기 위해 개의 형상을 띄는 무언가를 탐지하는 것을 확인할 수 있습니다. 또한 개의 형상과 더불어 아이의 형상을 띄는 부분도 확인할 수 있는데, 데이터셋 내에서 개의 이미지가 가족적인 이미지가 많이 포함되었다는 추측할 수 있습니다. (-> 우려되는 부분)
<Gradient ascent>

이런 이미지는 gradient ascent를 통해 얻을 수 있습니다.
모델을 학습할 때 backpropagation 알고리즘을 통해서 gradient descent 로 목적 함수인 loss들을 최소화하는 것과 마찬가지로 접근합니다.
이때 최적화에 사용하는 Loss fuction은 위와 같습니다.
- I 는 영상 입력입니다.
- 목표 : 전체 식을 최대화하는 것
- regularization term : 너무 큰 값을 가지지 않도록 제어하는 역할
- 먼저 f(I) 의 경우, 이미지를 CNN에 입력해주었을 때 출력된 하나의 클래스 스코어입니다. 따라서 argmax 항의 의미는 특정 클래스에 대한 클래스 스코어를 최대화하는 이미지 I 를 찾는 것이라고 볼 수 있습니다.
- 뒤의 regularization term의 경우 앞선 argmax 항에만 의존하여 결과값이 매우 커지는 경우 사람이 이미지의 형태로 파악하기 어려운 결과가 출력되는 것을 방지하기 위한 역할을 합니다. 따라서 이미지 I 의 L2 norm을 작게 만들도록 λ ∣∣I∣∣22 형태로 추가됩니다. λ값으로 작아지는 정도가 컨트롤됩니다.
이때 식의 부호만 바꿔주면 min 문제로 바뀌고 gradient descent 문제가 됩니다.
<동작 방법>

- 임의의 영상으로 분석하고자 하는 CNN 모델의 입력을 넣어줍니다. 그리고 관심 class score를 추출합니다. (이 방법은 중간단계를 분석하는 것이 아니라 최종 결론(CNN)에 대한 해석을 합니다.)
- backpropagation을 통해서 입력단의 gradient를 구합니다. 입력이 어떻게 변해야지 target class score가 높아지는지를 찾는 것입니다. target score를 높여주는 방향으로 input 이미지를 업데이트 해줍니다. loss를 측정할 때 score값에 마이너스를 붙여서 내려가는 방향으로 설정하고 gradient를 계산하면 이전에 neural network를 학습할 때 사용했던 gradient descent알고리즘을 그대로 사용하면 됩니다.
- 한번 입력을 업데이트 해줍니다.
- 업데이트된 영상으로부터 이 과정을 반복해 클래스에 대한 시각화 결과를 얻습니다. (score 계산 -> backpropagation -> update)
입력 영상은 회색과 같은 단조로운 영상도 괜찮고 랜덤 노이즈 이미지 등 어떤 이미지도 상관 없습니다. 하지만 어떤 입력을 넣어주냐에 따라서 입력에서부터 적절하게 바뀐 영상이 나오게 됩니다. (gradient descent는 현재 영상에서 어떻게 업데이트 할지 local search를 하기 때문) 조금씩 변화를 주면서 score를 높이는 방법을 찾습니다.
초기값을 어떻게 설정하냐에 따라서 다양한 결과를 얻을 수 있습니다. 따라서 여러번 이 과정을 거쳐서 패턴을 관찰하며 분석할 수 있습니다.
'Deep Learning > CV' 카테고리의 다른 글
| [boostcourse] CNN Visualization (1) : 동작 원리 (0) | 2024.06.17 |
|---|---|
| [boostcourse] 3. Seg&Det - Object Detection (0) | 2024.06.17 |
| [boostcourse] 3. Seg&Det - Semantic Segmentation (0) | 2024.06.17 |
| [boostcourse] 2. 컴퓨터 비전과 딥러닝 - 영상 인식의 이해 (2) | 2024.06.12 |
| [boostcourse] 2. 컴퓨터 비전과 딥러닝 - 데이터 부족 문제 완화 (1) | 2024.06.11 |



