
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- rnn
- LSTM
- 스택
- pytorch
- 최단 경로
- DFS
- 알고리즘
- AI
- 다이나믹 프로그래밍
- 선형대수
- 퀵정렬
- 그리디
- BFS
- 계수정렬
- 선택정렬
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 삽입정렬
- 재귀함수
- 인공지능
- 머신러닝
- RESNET
- 큐
- 정렬
- GRU
- 이진 탐색
- 딥러닝
- Machine Learning
- Today
- Total
hyeonzzz's Tech Blog
[Andrew Ng] 딥러닝 2단계 : 1. 머신러닝 어플리케이션 설정하기 본문
지금부터는 딥러닝의 실제적인 면을 다룸
- 하이퍼파라미터 튜닝
- 최적화 알고리즘의 속도를 높여 적당한 시간 안에 학습할 수 있는 방법
1. Train/Dev/Test 세트
▶ 신경망을 훈련시킬 때 결정 내려야 할 것
- 신경망이 몇 개의 층을 가지는지
- 각 층이 몇 개의 hidden unit을 가지는지
- 학습률과 활성화 함수는 무엇인지

(Idea → Code → Experiment) 반복하면서 하이퍼파라미터에 대한 선택을 개선한다!
딥러닝에 경험이 많은 사람도 첫 시도만에 하이퍼파라미터에 대한 정확한 추측을 할 순 없다
따라서, 중요한 것은
- 사이클을 효율적으로 도는 것
- 데이터 세트를 잘 설정하는 것
이다.
▶ Train/ dev/ test sets
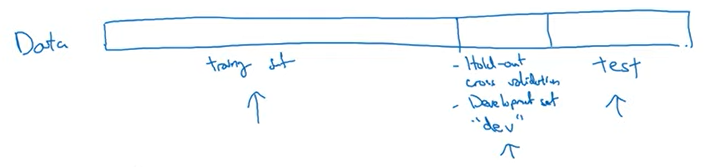
- train 세트 : 훈련을 위해 사용되는 데이터, 계속 훈련 알고리즘을 적용 시킴
- dev 세트 : 다양한 모델 중 어떤 모델이 좋은 성능 나타내는지 확인
- test 세트 : 최종 모델이 얼마나 잘 작동하는지 확인
▷ 머신러닝 이전의 시대 : 세트 크기가 별로 크지 않을 경우에는 따라도 된다
train - 70% / test - 30% or train - 60% / dev - 20% / test - 20%
▷ 빅데이터 시대 : dev 세트와 test 세트가 작은 비율이 되는 것이 트렌드
- 왜냐하면 서로 다른 알고리즘을 시험하고 평가할 수 있을 정도의 크기면 된다
(100만 개일 때) : 98% / 1% / 1%
(100만개보다 많을 때) : 99.5% / 0.25% / 0.25% or 99.5% / 0.4% / 0.1%
딥러닝의 또 다른 트렌드 : 많은 사람들이 일치하지 않는 train / test 분포에서 훈련시킨다
ex) train 세트 - 인터넷에서 긁어온 고양이 사진 / dev, test 세트 - 사용자에 의해 업로드된 저해상도 사진
→ 이런 경우 dev와 test 세트가 같은 분포여야 한다
비편향 추정이 필요 없는 경우 : test 세트를 갖지 않아도 된다 - train / test (dev를 test로 부름)
(test 세트의 목표는 최종 네트워크의 성능에 대한 비편향 추정을 제공하는 것이기 때문)
※ 비편향 추정 : 여러 번의 추정을 했을 때 그 예측값들의 평균이 실제 정답과 차이가 없다
2. 편향/분산

데이터가 있다고 했을 때 데이터에 맞는 직선을 넣는다.
특성 x1과 x2만을 갖는 2차원 예제에서는 편향과 분산을 시각화할 수 있다. 하지만 높은 차원의 문제에서는 데이터를 나타내거나 결정 경계를 시각화할 수 없다.
높은 편향 → 과소적합
높은 분산 → 과대적합

고양이 사진 분류 예제
높은 분산 - 훈련 세트에 과대적합되어 개발 세트에서 잘 분류X
고양이 사진을 인식하는 것은 사람들이 완벽히 할 수 있는 것이라고 가정해보자. 훈련 세트 오차가 1%라고 하고 개발 세트 오차는 11%라고 해보자. 따라서 이 같은 예제에서 훈련 세트에서는 매우 잘 분류됐지만 상대적으로 개발 세트에서는 잘 분류되지 못한 경우이다. 즉 훈련 세트에 과대적합이 되어서 개발 세트가 있는 교차 검증 세트에서 일반화되지 못한 경우이다. 이런 경우 높은 분산을 갖는다고 말한다.
높은 편향 - 훈련 세트에 과소적합
이제 훈련 세트 오차는 15%이고 개발 세트 오차는 16%라고 해보자. 이 경우에 인간은 대략 0%의 오차를 낸다고 가정해보자. 그럼 이 알고리즘은 훈련 세트에 대해서도 잘 작동되지 않는 것처럼 보인다. 훈련 데이터에 대해서도 잘 맞지 않는다면 데이터에 과소적합한 것이다. 따라서 높은 편향을 갖는다. 반면에 개발 세트의 성능이 훈련 세트보다 1% 밖에 나쁘지 않으므로 이것은 합리적인 수준의 개발 세트에서 일반화되고 있다.
높은 분산 높은 편향
훈련 세트 오차가 15%이고 개발 세트 오차가 30%라고 해보자. 이경우 훈련 세트에 잘 맞지 않으니 높은 편향이고 높은 분산도 갖는다.
낮은 분산 낮은 편향
훈련 세트 오차가 0.5%이고 개발 세트 오차가 1%라고 해보자. 이 경우 분류기의 편향과 분산이 모두 낮다.
이 분석은 인간 수준의 성능, 최적의 오차, 즉 베이지안 오차가 거의 0%이다. 하지만 최적 오차 혹은 베이즈 오차가 15%로 더 높은 경우에 훈련 세트 오차가 15%인 것은 아주 합당하다. 높은 편향이라고 부르지 않고 낮은 분산이라고 말하게 된다.
이미지가 아주 흐릿해서 인간 혹은 그 어떤 시스템도 잘 분류하지 못하는 경우에는 베이즈 오차는 훨씬 커질 것이고 이 분석에 대한 세부 방식은 달라질 것이다.
편향 문제 - 훈련 세트 오차를 확인해서 최소한 훈련 데이터에서 얼마나 알고리즘이 적합한지 감을 잡을 수 있다.
분산 문제 - 훈련 세트에서 개발 세트로 갈 때 오차가 얼마나 커지는지에 따라서 감을 잡을 수 있다.

이 모든 것은 베이즈 오차가 꽤 작고 훈련 세트와 개발 세트가 같은 확률 분포에서 왔다는 가정하에 이루어진다.

높은 편향과 높은 분산의 경우에는 어떻게 생겼을까?
선형의 분류기는 데이터에 과소적합하기 때문에 높은 편향을 갖는다. 따라서 보라색 분류기는 거의 선형이고 데이터에 과소적합할 것이다.
그러나 만약 분류기가 일부의 데이터에 과대적합한다면 보라색 분류기는 높은 편향과 높은 분산을 갖게 된다. 분류기는 거의 선형이지만 곡선이나 이차 함수가 필요하기 때문에 높은 편향을 갖는다. 또한 중간에 잘못 라벨링된 샘플을 맞추기 위해 너무 많은 굴곡을 갖기 때문에 높은 분산을 갖게 된다.
이 예제는 2차원이지만 매우 높은 차원의 입력에서는 어떤 영역은 높은 편향을 갖고 어떤 영역은 높은 분산을 갖게 된다.
3. 머신러닝을 위한 기본 레시피

1. 높은 편향인지 평가 - 훈련 세트 혹은 훈련 데이터의 성능을 봐야 한다
높은 편향을 가진다면 시도할 수 있는 것
- 더 많은 은닉 층 혹은 은닉 유닛을 갖는 네트워크를 선택
- 더 오랜 시간 훈련시킴
- 다른 최적화 알고리즘 사용
- 다른 신경망 아키텍처 찾기
2. 높은 분산인지 평가 - 개발 세트 성능을 봐야 한다
높은 분산을 가진다면 시도할 수 있는 것
- 데이터를 더 얻는 것
- 정규화를 시도
- 다른 신경망 아키텍처 찾기
이 방법들을 계속 시도하고 반복하면서 낮은 편향과 분산을 찾는다.
<편향-분산 트레이드오프>
예전에는 편향이 증가되면 분산이 감소되거나 편향이 감소되면 분산이 증가되었다.
하지만 딥러닝 시대에서는 더 큰 네트워크를 훈련시키고 더 많은 데이터를 얻는 것이 정규화를 올바르게 했다면 서로 영향을 미치지 않고 대부분 한쪽만을 감소시킨다. 더 큰 네트워크를 훈련시키는 것은 대부분 절대 해가 없다.
따라서 딥러닝이 지도 학습에 유용한 이유는 편향과 분산의 균형을 신경써야 하는 트레이드오프가 훨씬 적기 때문이다.
'Deep Learning > Basics' 카테고리의 다른 글
| [Andrew Ng] 딥러닝 1단계 : 4. 얕은 신경망 네트워크 -(2) (0) | 2024.01.20 |
|---|---|
| [Andrew Ng] 딥러닝 1단계 : 4. 얕은 신경망 네트워크 -(1) (0) | 2024.01.17 |
| [Andrew Ng] 딥러닝 1단계 : 3. 파이썬과 벡터화 (0) | 2023.09.19 |
| [Andrew Ng] 딥러닝 1단계 : 2. 신경망과 로지스틱회귀 (2) (0) | 2023.09.12 |
| [Andrew Ng] 딥러닝 1단계 : 2. 신경망과 로지스틱회귀 (1) (0) | 2023.09.12 |



