
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 캐치카페신촌점 #캐치카페 #카페대관 #대학생 #진학사 #취준생
- 딥러닝
- Machine Learning
- 다이나믹 프로그래밍
- 재귀함수
- 그리디
- RESNET
- 계수정렬
- 선택정렬
- 최단 경로
- 정렬
- LSTM
- DFS
- 머신러닝
- 큐
- pytorch
- 선형대수
- 삽입정렬
- 이진 탐색
- 퀵정렬
- AI
- 인공지능
- rnn
- 스택
- GRU
- BFS
- 알고리즘
- Today
- Total
hyeonzzz's Tech Blog
[딥러닝 파이토치 교과서] 7장. 시계열 분석 -(1) 본문
7.3 순환 신경망(RNN)
RNN(Recurrent Neural Network) : 시간적으로 연속성이 있는 데이터를 처리하려고 고안된 인공 신경망
- Recurrent - '이전 은닉층이 현재 은닉층의 입력이 되면서 반복되는 순환 구조를 갖는다'는 의미
- 기존 네트워크와 다른 점은 '기억(memory)'을 갖는다는 것이다
- 기억 - 현재까지 입력 데이터를 요약한 정보
- 새로운 입력이 네트워크로 들어올 때마다 기억은 조금씩 수정되며, 결국 최종적으로 남겨진 기억은 모든 입력 전체를 요약한 정보가 된다

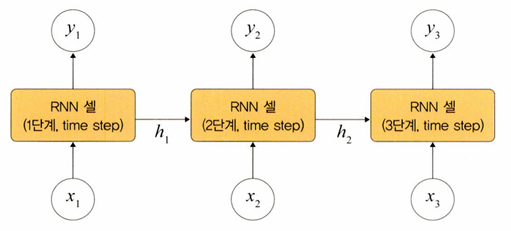
그림과 같이 첫 번째 입력(x1)이 들어오면 첫 번째 기억(h1)이 만들어지고,
두 번째 입력(x2)이 들어오면 기존 기억(h1)과 새로운 입력을 참고하여 새 기억(h2)을 만든다.
입력 길이만큼 이 과정을 얼마든지 반복할 수 있다.
즉, RNN은 외부 입력과 자신의 이전 상태를 입력받아 현재 상태를 갱신한다.
입력과 출력에 따른 RNN 유형
- 일대일 : 순환이 없기 때문에 RNN이라고 말하기 어렵다. 순방향 네트워크가 대표적 사례이다.
- 일대다 : 입력이 1개이고, 출력이 다수이다. 이미지를 입력해서 이미지에 대한 설명을 문장으로 출력하는 이미지 캡션(image captioning)이 대표적 사례이다.
- 다대일 : 입력이 다수이고 출력이 1개이다. 문장을 입력해서 긍정/부정을 출력하는 감성 분석기에서 사용된다.
- 다대다 : 입력과 출력이 다수인 구조이다. 언어를 번역하는 자동 번역기 등이 대표적인 사례이다.
- 동기화 다대다 : 입력과 출력이 다수인 구조이다. 문장에서 다음에 나올 단어를 예측하는 언어 모델, 즉 프레임 수준의 비디오 분류가 대표적 사례이다.
다대일 모델 구현 코드
self.em = nn.Embedding(len(TEXT.vocab.stoi), embeding_dim) # 임베딩 처리
self.rnn = nn.RNNCell(input_dim, hidden_size) # RNN 적용
self.fc1 = nn.Linear(hidden_size, 256) # 완전연결층
self.fc2 = nn.Linear(256, 3) # 출력층
코드는 입력과 출력 사이에 하나의 RNN 셀(cell)만 가지고 있는 것이다
다대일 모델 vs 적층된 다대일 모델


다대일 구조에 층을 쌓아 올리면 적층된 구조를 가질 수 있다
다대다 모델 구현 코드
Seq2Seq(
(encoder) : Encoder(
(embedding) : Embedding(7855, 256)
(rnn) : LSTM(256, 512, num_layers=2, dropout=0.5)
(dropout) : Dropout(p=0.5, inplace=False)
)
(decoder) : Decoder(
(embedding) : Embedding(5893, 256)
(rnn) : LSTM(256, 512, num_layers=2, dropout=0.5)
(fc_out) : Linear(in_features=512, out_features=5893, bias=True)
(dropout) : Dropout(p=0.5, inplace=False)
)
)
문장 번역에서 많이 사용되는 시퀀스-투-시퀀스(seq2seq)를 이용하는 방식으로 사용된다
다대다 모델
RNN 구조 그림

7.3.1 RNN 계층과 셀
- RNN은 내장된 계층뿐만 아니라 셀 레벨의 API도 제공한다
- RNN 계층이 입력된 배치 순서대로 모두 처리하는 것과 다르게 RNN 셀은 오직 하나의 단계만 처리한다
- 따라서 RNN 셀은 RNN 계층의 for loop 구문을 갖는 구조이다
RNN 계층과 RNN 셀

RNN 계층은 셀을 래핑하여 동일한 셀을 여러 단계에 적용한다.
(래핑 - dll이나 API를 사용하기 쉽도록 한 번 더 dll 등으로 만들어 주는 것)
위의 그림에서도 X1, X2, ..., Xn 등이 전체 RNN 셀에서 사용되고 있다.
즉, 셀은 실제 계산에 사용되는 RNN 계층의 구성 요소로, 단일 입력과 과거 상태(state)를 가져와서 출력과 새로운 상태를 생성한다.
셀 유형
- nn.RNNCell : SimpleRNN 계층에 대응되는 RNN 셀
- nn.GRUCell : GRU 계층에 대응되는 GRU 셀
- nn.LSTMCell : LSTM 계층에 대응되는 LSTM 셀
RNN 계층과 셀을 분리해서 설명하는 이유는 파이토치에서 둘을 분리해서 구현이 가능하기 때문이다.
RNN의 활용 분야
- 자연어 처리 : 연속적인 단어들의 나열인 자연어 처리는 음성 인식, 단어의 의미 판단 및 대화 등에 대한 처리가 가능하다. 이외에도 손글씨, 센서 데이터 등 시계열 데이터 처리에 활용된다.
7.4 RNN 구조
RNN : 은닉층 노드들이 연결되어 이전 단계 정보를 은닉층 노드에 저장할 수 있도록 구성한 신경망

위 그림에서 볼 수 있듯이 x_t-1에서 h_t-1을 얻고
다음 단계에서 h_t-1과 x_t를 사용하여 과거 정보와 현재 정보를 모두 반영한다.
또한, h_t와 x_t+1의 정보를 이용하여 과거와 현재 정보를 반복해서 반영한다.
RNN의 가중치
RNN에서는 입력층, 은닉층, 출력층 외에 가중치를 3개 가진다.
- W_xh : 입력층에서 은닉층으로 전달되는 가중치
- W_hh : t 시점의 은닉층에서 t+1 시점의 은닉층으로 전달되는 가중치
- W_hy : 은닉층에서 출력층으로 전달되는 가중치
※ 가중치 W_xh, W_hh, W_hy는 모든 시점에 동일하다
t 단계에서의 RNN 계산
1. 은닉층
계산을 위해 x_t와 h_t-1이 필요하다.
RNN에서 은닉층은 일반적으로 하이퍼볼릭 탄젠트 활성화 함수를 사용한다.

2. 출력층
심층 신경망과 계산 방법이 동일하다.
소프트맥스 함수를 적용한다.

3. 오차(E)
심층 신경망에서 전방향 학습과 달리 각 단계(t)마다 오차를 측정한다.
즉, 각 단계마다 실제 값(y_t)과 예측 값(y_t^)으로 오차를 이용하여 측정한다. (평균 제곱 오차(mean square error) 적용)

4. 역전파
BPTT(BackPropagation Through Time)를 이용하여 모든 단계마다 처음부터 끝까지 역전파한다.
BPTT : 각 단계(t)마다 오차를 측정하고 이전 단계로 전달되는 것
즉, 3에서 구한 오차를 이용하여 W_xh, W_hh, W_hy 및 bias를 업데이트한다.
이때 BPTT는 오차가 멀리 전파될 때 계산량이 많아지고 기울기 소멸 문제(vanishing gradient problem - 전파되는 양이 점차 적어지는 문제점)이 발생한다.
기울기 소멸 문제를 보완하기 위해 오차를 몇 단계까지만 전파시키는 생략된-BPTT(truncated BPTT)를 사용할 수도 있고, 근본적으로는 LSTM 및 GRU를 많이 사용한다.
※ 생략된-BPTT(truncated BPTT)
: 계산량을 줄이기 위해 현재 단계에서 일정 시점까지만 오류를 역전파하는 것

7.4.1 RNN 셀 구현
IMDB 데이터셋
: 영화 리뷰에 대한 데이터 5만 개로 구성되어 있다
- 이것을 훈련 데이터 2만 5000개와 테스트 데이터 2만 5000개로 나누며, 각각 50%씩 긍정 리뷰와 부정 리뷰가 있다
- 이미지 전처리가 되어 있어 각 리뷰가 숫자로 변환되어 있다
- imdb.load_data() 메서드로 바로 내려받아 사용할 수 있도록 지원한다
torchtext
: 자연어 처리(NLP) 분야에서 사용하는 데이터로더
- 파일 가져오기, 토큰화, 단어 집합 생성, 인코딩, 단어 벡터 생성 등의 작업을 지원한다
- 토큰화 : 텍스트를 문장이나 단어로 분리하는 것
- 단어 집합 : 중복을 제거한 텍스트의 총 단어의 집합
- 인코딩 : 문자를 컴퓨터의 언어인 숫자로 바꾸는 것
- 단어 벡터 : 단어의 가치 있는 의미를 나타내는 벡터
<데이터 전처리>
torchtext.legacy.data.Field(lower=True, fix_length=200, batch_first=False)- lower : 대문자 -> 소문자, 기본값은 false
- fix_length : 데이터의 길이를 200으로 고정, 200보다 짧다면 패딩 작업을 통해 맞춰준다
- batch_first : 신경망에 입력되는 텐서의 첫 번째 차원 값이 배치 크기가 되도록 한다. 즉, [배치 크기, 시퀀스 길이, 은닉층의 뉴런 개수] 형태로 변경된다. (참고로 은닉층의 입력 데이터는 batch_first=True 옵션과는 무관하게 [은닉층 개수, 배치 크기, 은닉층의 뉴런 개수]이다.)
TEXT.build_vocab(train_data, max_size=10000, min_freq=10, vectors=None)- 단어 집합 생성
- 첫 번째 파라미터 : 훈련 데이터셋
- max_size : 단어 집합에 포함되는 어휘 수
- min_freq : 훈련 데이터셋에서 특정 단어의 최소 등장 횟수
- vectors : 임베딩 벡터 지정. 사전 학습된 임베딩으로는 Word2Vector, Glove 등이 있으며, 파이토치에서도 nn.embedding()을 통해 단어를 랜덤한 숫자 값으로 변환한 후 가중치를 학습하는 방법을 제공한다
- vectors=None을 사용하면 임베딩을 사용하지 않고 단어의 정수 인덱스만을 가지는 단어 집합이 구축된다
LABEL이 3개라고 출력되는 이유?
pos, neg 외에 <unk>가 있다. 일반적으로 <unk>는 사전에 없는 단어를 의미한다. 따라서 예제에서 사용하는 것은 pos와 neg가 된다.
은닉층의 유닛 개수 지정

- 일반적으로 계층의 유닛 개수를 늘리는 것보다 계층 자체에 대한 개수를 늘리는 것이 성능에 좋다
- 은닉층 층수는 비선형 문제를 더 잘 학습할 수 있도록 하는 반면, 층 안에 포함된 뉴런은 가중치와 바이어스를 계산하는 용도로 사용되기 때문이다
- 최적의 은닉층 개수와 유닛 개수를 찾는 것은 매우 어려운 일이다
train_iterator, valid_iterator, test_iterator = torchtext.legacy.data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)- BucketIterator : 데이터로더와 쓰임새가 같다. 배치 단위로 값을 차례대로 꺼내어 메모리로 가져온다.
- 특히 Field에서 fix_length를 사용하지 않았다면 BucketIterator에서 데이터의 길이를 조정할 수 있다.
- BucketIterator는 비슷한 길이의 데이터를 한 배치에 할당하여 패딩을 최소화시켜준다.
파라미터 설명
- (train_data, valid_data, test_data) : 배치 크기 단위로 데이터를 가져올 데이터셋
- batch_size : 한번에 가져올 데이터 크기
- device : CPU/GPU 지정
<RNN 셀 정의>
ht = self.rnn(word, ht)
- ht : 현재 상태. 위 그림의 ht
- word : 현재의 입력 벡터. 위 그림의 xt. (batch, input_size)의 형태
- ht : 이전 상태. 위 그림의 ht-1. (batch, hidden_size)의 형태
<옵티마이저와 손실 함수 정의>
loss_fn = nn.CrossEntropyLoss()- torch.nn.CrossEntropyLoss : 다중 분류에 사용
- nn.LogSoftmax와 nn.NLLLoss 연산의 조합으로 구성된다
- nn.LogSoftmax : 모델 네트워크의 마지막 계층에서 얻은 결괏값들을 확률로 해석하기 위해 소프트맥스 함수의 결과에 log를 취한 것
- nn.NLLLoss : 다중 분류에 사용
- 신경망에서 로그 확률 값을 얻으려면 마지막에 LogSoftmax를 추가해야 한다
7.4.2 RNN 계층 구현
RNN 계층은 RNN 셀의 네트워크와 크게 다르지 않기 때문에 미세한 차이 위주로 학습한다
<RNN 계층 네트워크>
h_0 = self._init_state(batch_size = x.size(0))
일반적으로 RNN의 첫 번째 은닉 상태는 모두 0으로 초기화된다.
이는 모델이 새로운 입력 시퀀스를 처리하기 전에 모든 기억과 상태를 잊고 새로운 정보를 받아들이기 위함이다.
0으로 초기화된 은닉 상태는 모델이 처음 입력을 처리할 때 해당 입력의 컨텍스트를 고려하지 않고 처리하기 시작하도록 한다. 이렇게 함으로써 모델은 처음 입력과 이후 입력 사이의 관계를 학습할 수 있다.
<모델 학습 함수>
y.data.sub_(1)
- sub_() : 뺄셈에 대한 함수
- _이 붙은 것은 inplace 연산을 하겠다는 의미이다.
- inplace 연산 : 새로운 텐서를 생성하지 않고 기존의 텐서를 직접 수정할 것인지
- IMDB 레이블은 긍정은 2, 부정은 1의 값을 갖는다
- 따라서 y.data에서 1을 뺀다는 것은 레이블 값을 0과 1로 변환하겠다는 의미이다
<모델 평가 함수>
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()- 모델의 정확도를 구한다
- max(1)[1] : .max(dim=0)[0]은 최댓값을 나타내고 .max(dim=0)[1]은 최댓값을 갖는 데이터의 인덱스를 나타낸다
- view(y.size()) : logit.max(1)[1]의 결과를 y.size()로 크기를 변경한다
- data == y.data : 모델의 예측 결과가 레이블(실제 값, y.data)과 같은지 확인한다
- sum() : 모델의 예측 결과와 레이블(실제 값)이 같으면 그 합을 corrects 변수에 누적하여 저장한다
7.5 LSTM
RNN의 단점
: 가중치가 업데이트되는 과정에서 기울기가 1보다 작은 값이 계속 곱해지기 때문에 기울기가 사라지는 기울기 소멸 문제가 발생한다.
-> LSTM이나 GRU 같은 확장된 RNN 방식들 사용한다
7.5.1 LSTM 구조
LSTM 순전파
LSTM은 기울기 소멸 문제를 해결하기 위해 망각 게이트, 입력 게이트, 출력 게이트라는 새로운 요소를 은닉층의 각 뉴런에 추가했다.
1. 망각 게이트(forget gate)
: 과거 정보를 어느 정도 기억할지 결정
- 과거 정보와 현재 데이터를 입력받아 시그모이드를 취한 후 그 값을 과거 정보에 곱해준다.
- 시그모이드의 출력이 0이면 과거 정보는 버리고, 1이면 과거 정보는 온전히 보존한다.
- 새로운 입력 값 x_t와 이전 은닉층에서 입력되는 값 h_t-1을 입력 값으로 받는다.
- h_t-1과 x_t를 이용하여 이전 상태 정보를 현재 메모리에 반영할지 결정한다.
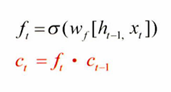

2. 입력 게이트(input gate)
: 현재 정보를 기억하기 위해 만들어졌다
- 과거 정보와 현재 데이터를 입력받아 시그모이드와 하이퍼볼릭 탄젠트 함수를 기반으로 현재 정보에 대한 보존량을 결정한다
- 현재 메모리에 새로운 정보를 반영할지 결정하는 역할을 한다
- 1이면 입력 x_t가 들어올 수 있도록 허용하고, 0이면 차단한다


3. 셀
: 각 단계에 대한 은닉 노드(hidden node)를 메모리 셀이라고 한다.
- 총합(sum)을 사용하여 셀 값을 반영하며, 이것으로 기울기 소멸 문제가 해결된다.
- 셀을 업데이트하는 방법 : 망각 게이트와 입력 게이트의 이전 단계 셀 정보를 계산하여 현재 단계의 셀 상태(cell state)를 업데이트한다.



4. 출력 게이트(output gate)
: 과거 정보와 현재 데이터를 사용하여 뉴런의 출력을 결정한다.
- 이전 은닉 상태(hidden state)와 t번째 입력을 고려해서 다음 은닉 상태를 계산한다
- LSTM에서는 이 은닉 상태가 그 시점에서의 출력이 된다
- 출력 게이트는 갱신된 메모리의 출력 값을 제어하는 역할을 한다
- 계산한 값이 1이면 의미 있는 결과로 최종 출력, 0이면 해당 연산 출력을 하지 않는다



LSTM 전체 게이트

LSTM 역전파
LSTM은 셀을 통해서 역전파를 수행하기 때문에 '중단 없는 기울기(uninterrupted gradient flow)'라고도 한다.
LSTM 셀 단위 역전파

위 그림과 같이 최종 오차는 모든 노드에 전파되는데, 이때 셀을 통해서 중단 없이 전파된다
역전파를 수행하기 위한 공식

주의해야 할 것은 셀 단위로 오차가 전파된다고 해서 입력 방향으로 오차가 전파되지 않는 것은 아니라는 것이다.

위 그림처럼 셀 내부적으로는 오차가 입력(xt)으로 전파된다는 것을 기억해야 한다.
7.5.2 LSTM 셀 구현
MNIST 데이터셋
: 손으로 쓴 숫자 이미지들로 구성되어 있다.
- 훈련 데이터셋 6만 개와 검증 데이터셋 1만 개로 구성되어 있다.
- 0에서 9까지 값을 갖는 고정 크기 이미지(28 x 28 픽셀)들로 구성되어 있다.
<LSTM 셀 네트워크 구축>
self.x2h = nn.Linear(input_size, 4 * hidden_size, bias=bias)
왜 은닉층의 유닛에 4를 곱할까?

LSTM에서 중요한 것은 게이트이다.
게이트는 망각, 입력, 셀, 출력으로 구성되며 모든 게이트는 다음처럼 구할 수 있다.
gates = F.linear(input, w_ih, b_ih) + F.linear(hx, w_hh, b_hh)- input : 입력층으로 입력되는 훈련 데이터셋의 특성 수
- w_ih : 입력층과 은닉층 사이의 가중치
- b_ih : 입력층과 은닉층 사이의 바이어스
- hx : 은닉층의 유닛 개수(은닉층의 feature 수)
- w_hh : 은닉층과 은닉층 사이의 가중치
- b_hh : 은닉층과 은닉층 사이의 바이어스
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
- 계산된 게이트는 gates.chunk(4, 1)에 의해 4개로 쪼개져서 각각 망각, 입력, 셀, 출력 게이트를 의미하는 변수에 저장된다.
- 즉, gates가 4개로 쪼개지는 상황이기 때문에 4가 곱해졌던 것이다.
- 일반적으로 바이어스도 4를 곱해준다.
- torch.chunk : 텐서를 쪼갤 때 사용하는 함수
- 첫 번째 파라미터 : 텐서를 몇 개로 쪼갤지
- 두 번째 파라미터 : 어떤 차원을 기준으로 쪼갤지. dim=1이므로 열 단위로 텐서를 분할하겠다는 의미이다.
난수 사용방법
from random import *
ri = randint(1, 10) # 1부터 10 사이의 임의의 정수
rd = random() # 0부터 1 사이의 임의의 실수(float)
ui = uniform(1, 10) # 1부터 10 사이의 임의의 실수(float)
rr = randrange(1, 10, 2) # 1부터 10 사이를 2씩 건너뛴 임의의 정수
<모델 예측 결과 출력>
plt.axvline(x=200, c='r', linestyle='--')- x=200 : 어떤 지점에 수직선을 표현할지
- c='r' : 어떤 색상으로 수직선을 표현할지
- linestyle : 어떤 스타일로 수직선을 표현할지. (수평선은 axhline())
※ LSTM에서 셀 상태와 은닉 상태의 역할
- 셀 상태(Cell State):
- 셀 상태는 LSTM의 핵심 메모리 부분이다.
- 셀 상태는 시간에 따라 정보를 전달하는 역할을 한다.
- 셀 상태는 게이트(gate)라 불리는 세 개의 시그모이드(sigmoid) 함수로 구성된 복잡한 방정식에 의해 업데이트된다.
- 셀 상태는 장기적인 의존성을 학습하고 기억하는 데 사용됩니다.
- 은닉 상태(Hidden State):
- 은닉 상태는 현재 시간 단계의 출력(output)이다.
- 은닉 상태는 현재 입력과 이전 시간 단계의 은닉 상태 및 셀 상태에 의해 계산됩니다.
- 은닉 상태는 현재 입력에 대한 정보를 포함하며, 다음 시간 단계의 은닉 상태를 계산하는 데 사용됩니다.
- 은닉 상태는 시퀀스 데이터의 특징을 학습하는 데 중요한 역할을 합니다.
간단히 말해, 셀 상태는 장기적인 의존성을 기억하고 전달하는 데 사용되며, 은닉 상태는 현재 입력에 대한 정보를 포함하고 다음 단계의 은닉 상태를 계산하는 데 사용된다. 이러한 구조는 시퀀스 데이터를 처리하면서 장기적인 의존성을 효과적으로 학습할 수 있도록 도와준다.
'Deep Learning > Pytorch' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 8장. 성능 최적화 (0) | 2024.05.15 |
|---|---|
| [딥러닝 파이토치 교과서] 7장. 시계열 분석 -(2) (0) | 2024.05.14 |
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(2) (1) | 2024.05.03 |
| [딥러닝 파이토치 교과서] 6장. 합성곱 신경망 Ⅱ -(1) (0) | 2024.04.12 |
| [딥러닝 파이토치 교과서] 5장. 합성곱 신경망 I -(2) (2) | 2024.04.03 |



